Event Sourcing Pattern
Event sourcing is a persistence pattern in which the state of an application entity is derived entirely from a chronologically ordered, immutable sequence of events rather than from a single mutable record in a database.
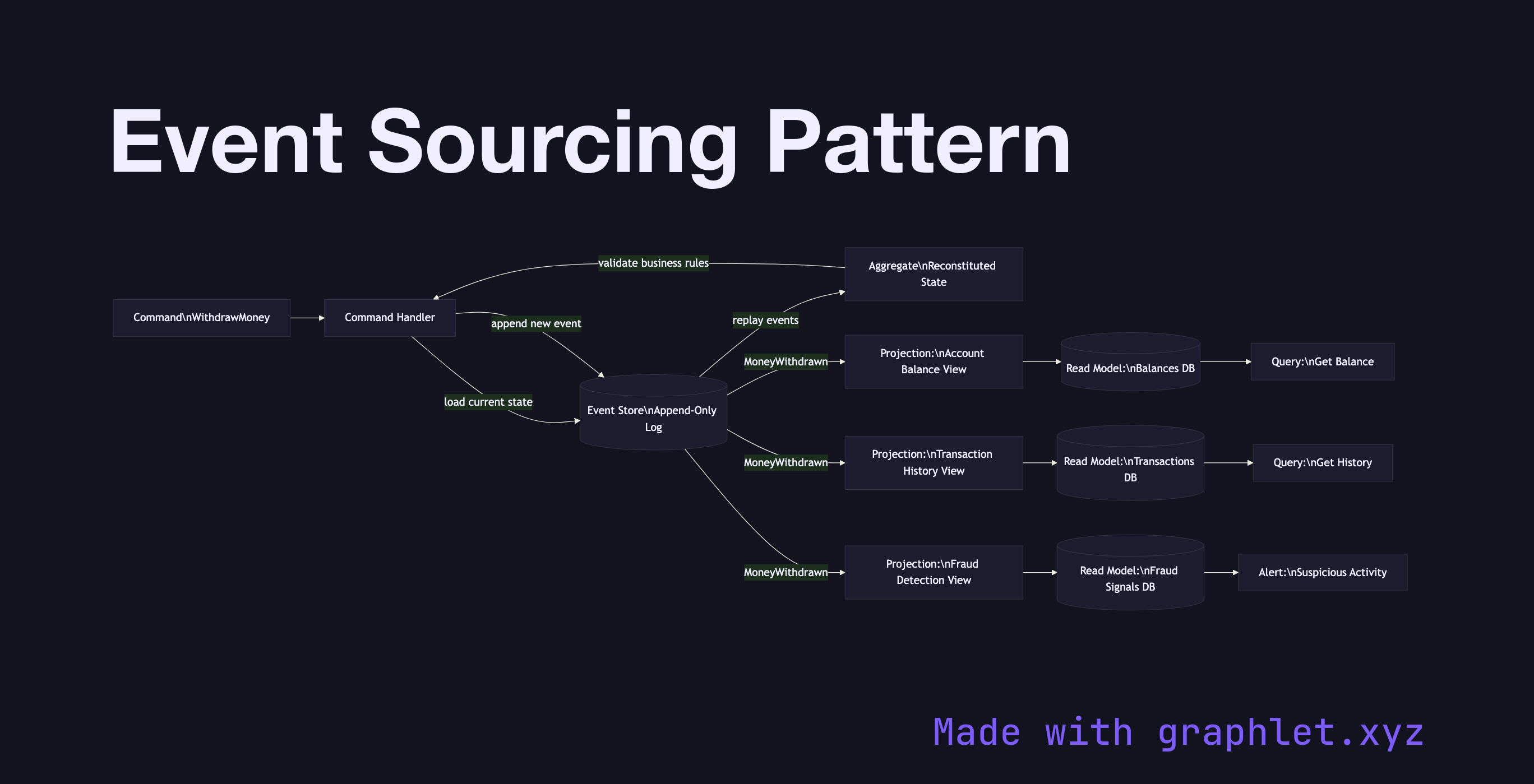
Event sourcing is a persistence pattern in which the state of an application entity is derived entirely from a chronologically ordered, immutable sequence of events rather than from a single mutable record in a database.
In a conventional CRUD system, updating a bank account balance means executing UPDATE accounts SET balance = balance - 100. The previous balance is gone. Event sourcing instead records MoneyWithdrawn { amount: 100, timestamp: ... } as an immutable fact in an event store. The current balance is derived on demand by replaying all events for that account from the beginning: deposits added, withdrawals subtracted.
This approach unlocks capabilities that CRUD systems cannot offer. The complete audit trail is built in — you can answer "what was the balance at 3pm last Tuesday?" by replaying events up to that timestamp. Bugs in business logic can be corrected by fixing the projection and replaying historical events to rebuild the read model. New features that need historical data can be added after the fact, because the raw events still exist.
The event store is append-only: events are never updated or deleted. Write operations go through a command handler that validates business rules (the current aggregate state, reconstituted from events, is checked), then appends new events. Projections subscribe to the event stream and build read models — denormalized query-optimized views — for the application's UI and API layers. Multiple projections can consume the same event stream to serve different read patterns.
Event sourcing is often paired with CQRS (Command Query Responsibility Segregation), where write and read paths are fully separated. It also integrates naturally with Event Streaming Architecture when Kafka serves as the event store, and with Saga Pattern for multi-aggregate workflows.