MVCC Workflow
Multi-Version Concurrency Control (MVCC) is a concurrency strategy used by databases like PostgreSQL, MySQL InnoDB, and Oracle to allow readers and writers to operate on the same data simultaneously without blocking each other.
Multi-Version Concurrency Control (MVCC) is a concurrency strategy used by databases like PostgreSQL, MySQL InnoDB, and Oracle to allow readers and writers to operate on the same data simultaneously without blocking each other.
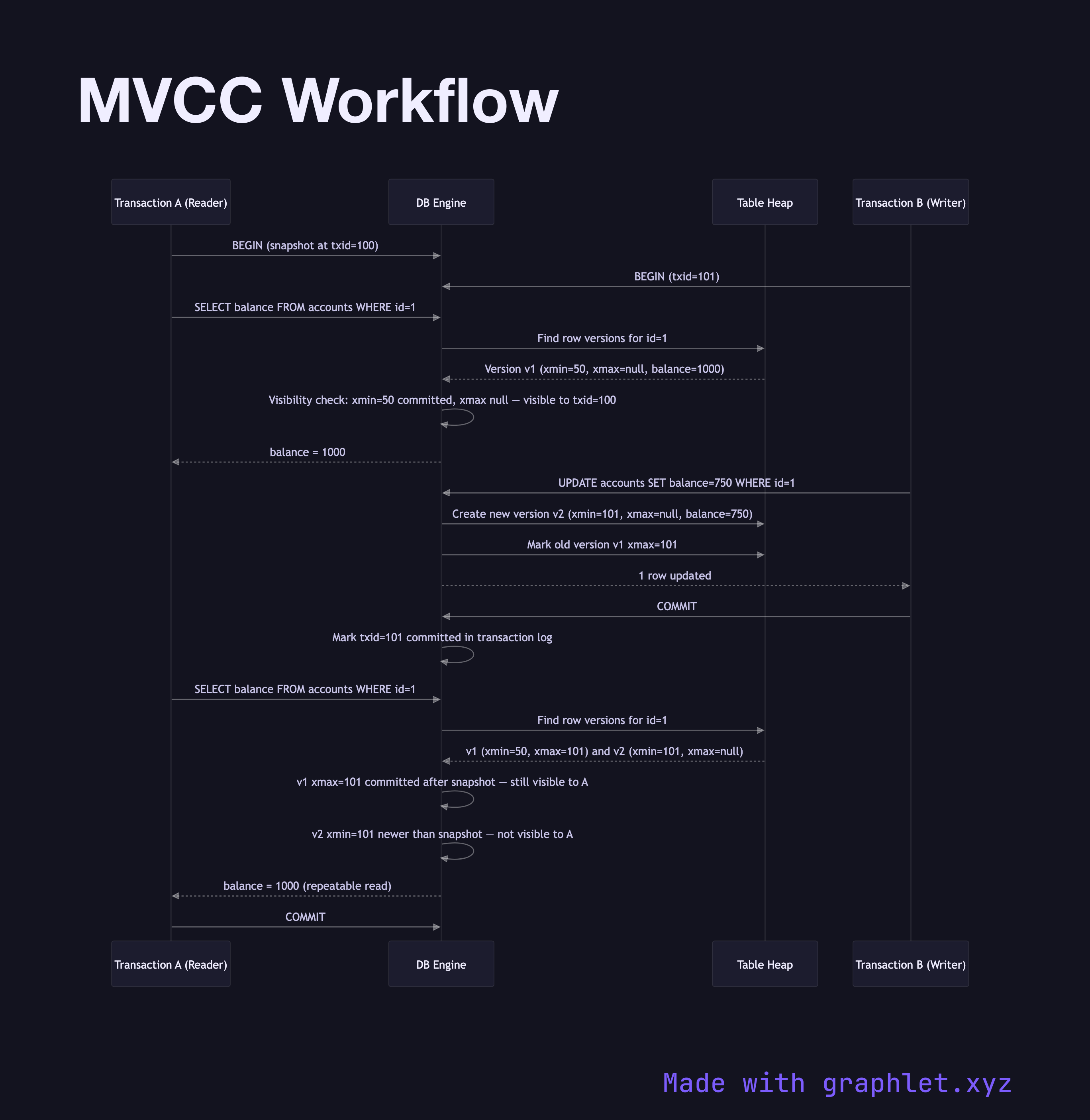
This sequence diagram shows two concurrent transactions — a reader (Transaction A) and a writer (Transaction B) — operating on the same row. When Transaction B writes an updated value to a row, the database does not overwrite the existing version. Instead, it creates a new row version tagged with B's transaction ID and a xmin timestamp. The old version remains visible in the heap, tagged with its original xmin and with xmax set to B's transaction ID to indicate it is being superseded.
Transaction A, which started before B's write, holds a snapshot taken at its BEGIN time. When A reads the row, the database evaluates visibility rules: it checks whether the row version's xmin is committed and visible to A's snapshot, and whether the version's xmax is either absent or refers to a transaction that was not yet committed when A's snapshot was taken. The old version satisfies these rules — so A sees the pre-update value. The new version created by B is not visible to A because B's transaction ID is newer than A's snapshot horizon.
This is what makes MVCC powerful: readers never block writers and writers never block readers. The cost is storage overhead — every update creates a new version, and old versions accumulate until the database's garbage collector (VACUUM in PostgreSQL) identifies and reclaims versions no longer needed by any active transaction.
MVCC underpins the Isolation levels described in ACID Properties. Read Committed mode takes a new snapshot per statement; Repeatable Read takes a snapshot once at BEGIN and holds it for the transaction's duration, as shown in this diagram.