Database Index Lookup
A database index lookup is the process by which the query engine uses an auxiliary data structure — typically a B-tree — to find the physical location of rows matching a WHERE clause predicate without scanning the entire table.
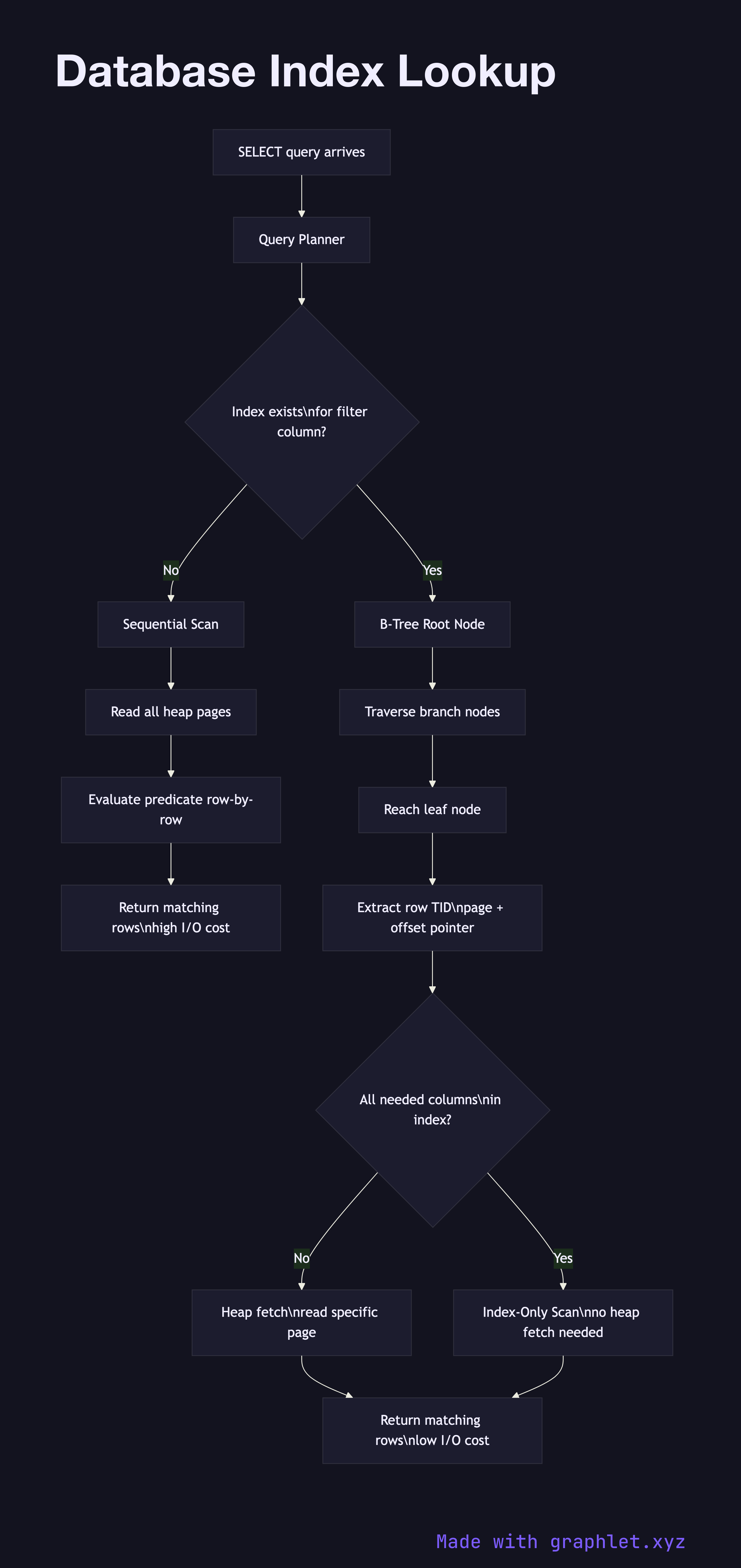
A database index lookup is the process by which the query engine uses an auxiliary data structure — typically a B-tree — to find the physical location of rows matching a WHERE clause predicate without scanning the entire table.
This diagram shows the decision point between an index scan and a sequential scan. When a query arrives at the planner, it checks whether a suitable index exists for the filter columns. If no index is available, the engine performs a sequential scan — it reads every page in the table heap from disk, evaluating the predicate row-by-row. For small tables this is fine; for millions of rows it is catastrophically slow.
When an index is present, the engine traverses the B-tree from the root node down through branch nodes until it reaches a leaf. Each leaf entry stores the indexed column value alongside a tuple identifier (TID) — a (page, offset) pair pointing to the actual row in the heap. The engine then performs a heap fetch using the TID, reading only the specific heap pages that contain matching rows.
For queries that request only columns present in the index itself — the indexed column plus any columns added as INCLUDE columns — the engine can satisfy the query from the index alone without heap fetches. This is called an index-only scan and is significantly faster for large tables.
Understanding index lookups directly informs how you write queries and design schemas. Composite indexes are only used when the leftmost prefix of the index matches the query predicates. An index on (last_name, first_name) accelerates WHERE last_name = 'Smith' but not WHERE first_name = 'Alice'. The Query Execution Plan diagram shows how the planner chooses between these strategies using cost estimates.