Kafka Partitioning
Kafka partitioning is the mechanism by which a topic's message stream is divided into ordered, immutable sublogs that can be stored and processed in parallel across multiple brokers.
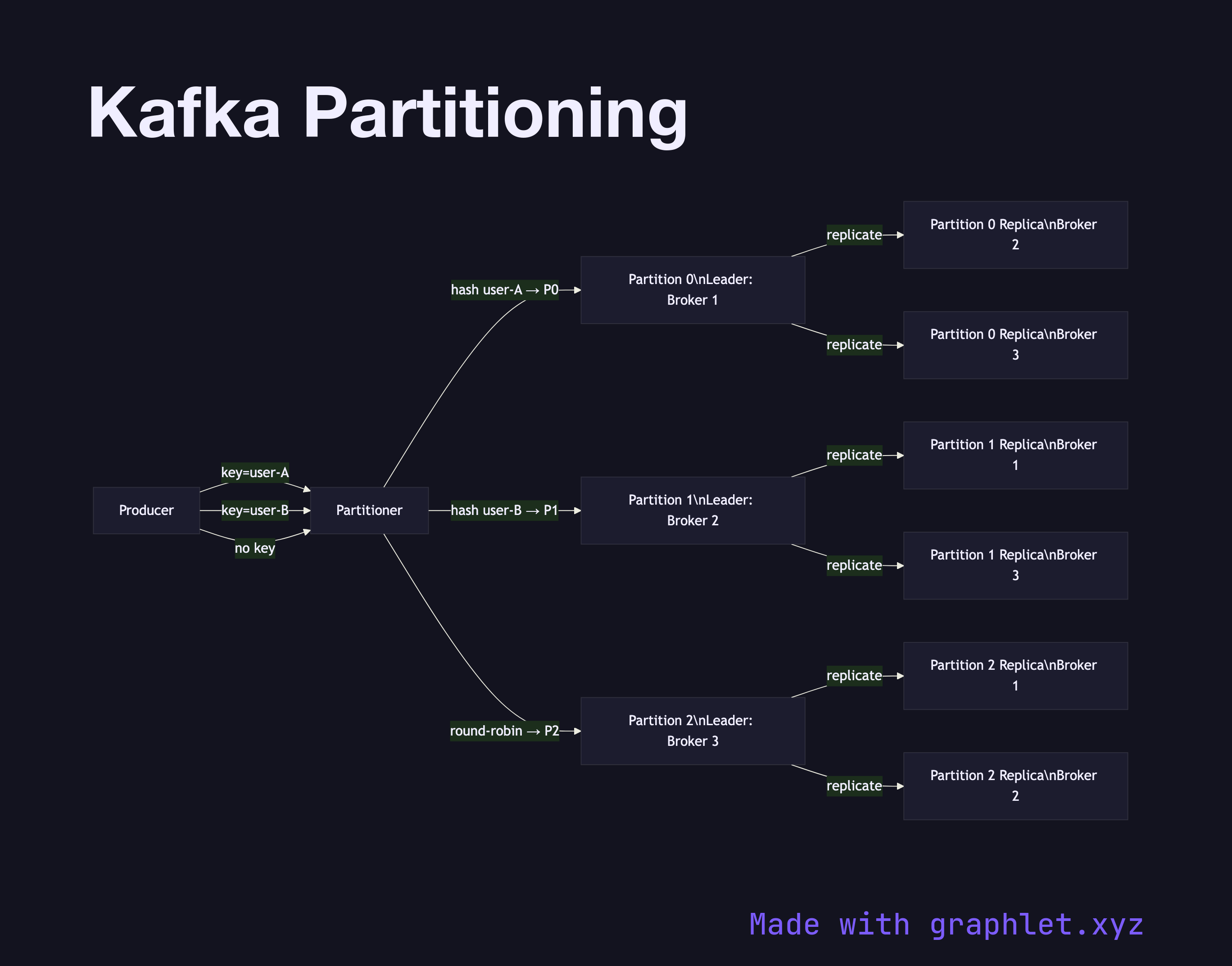
Kafka partitioning is the mechanism by which a topic's message stream is divided into ordered, immutable sublogs that can be stored and processed in parallel across multiple brokers.
A Kafka topic is a logical channel, but data is never stored at the topic level — it lives in partitions. Each partition is an append-only, ordered log that resides on a single broker (the leader) and is replicated to one or more other brokers (the followers). Partitioning achieves two goals simultaneously: it allows topics to scale beyond a single machine's I/O capacity, and it provides the unit of parallelism for consumers.
When a producer sends a record, the partitioner decides which partition receives it. The default strategy hashes the message key: records with the same key always land in the same partition, which is the primary tool for enforcing ordering by entity (e.g., all events for user-123 go to partition 2). Without a key, the partitioner uses round-robin, distributing load evenly but abandoning per-entity order guarantees. See Message Ordering Guarantee for how this plays out downstream.
Replication works at the partition level. The leader handles all reads and writes; followers pull and replicate. If the leader broker fails, one of the in-sync replicas (ISR) is elected as the new leader — a process managed by ZooKeeper (legacy) or KRaft (modern). The min.insync.replicas setting controls how many replicas must confirm a write before the producer receives an ack, directly trading latency for durability.
Understanding partitioning is prerequisite knowledge for tuning the Kafka Consumer Group assignment (you can't have more consumers than partitions) and for designing the Event Streaming Architecture that sits around it.