CAP Theorem Model
The CAP theorem states that a distributed data system can provide at most two of three properties simultaneously: Consistency, Availability, and Partition Tolerance — and that in the presence of a network partition, you must choose between consistency and availability.
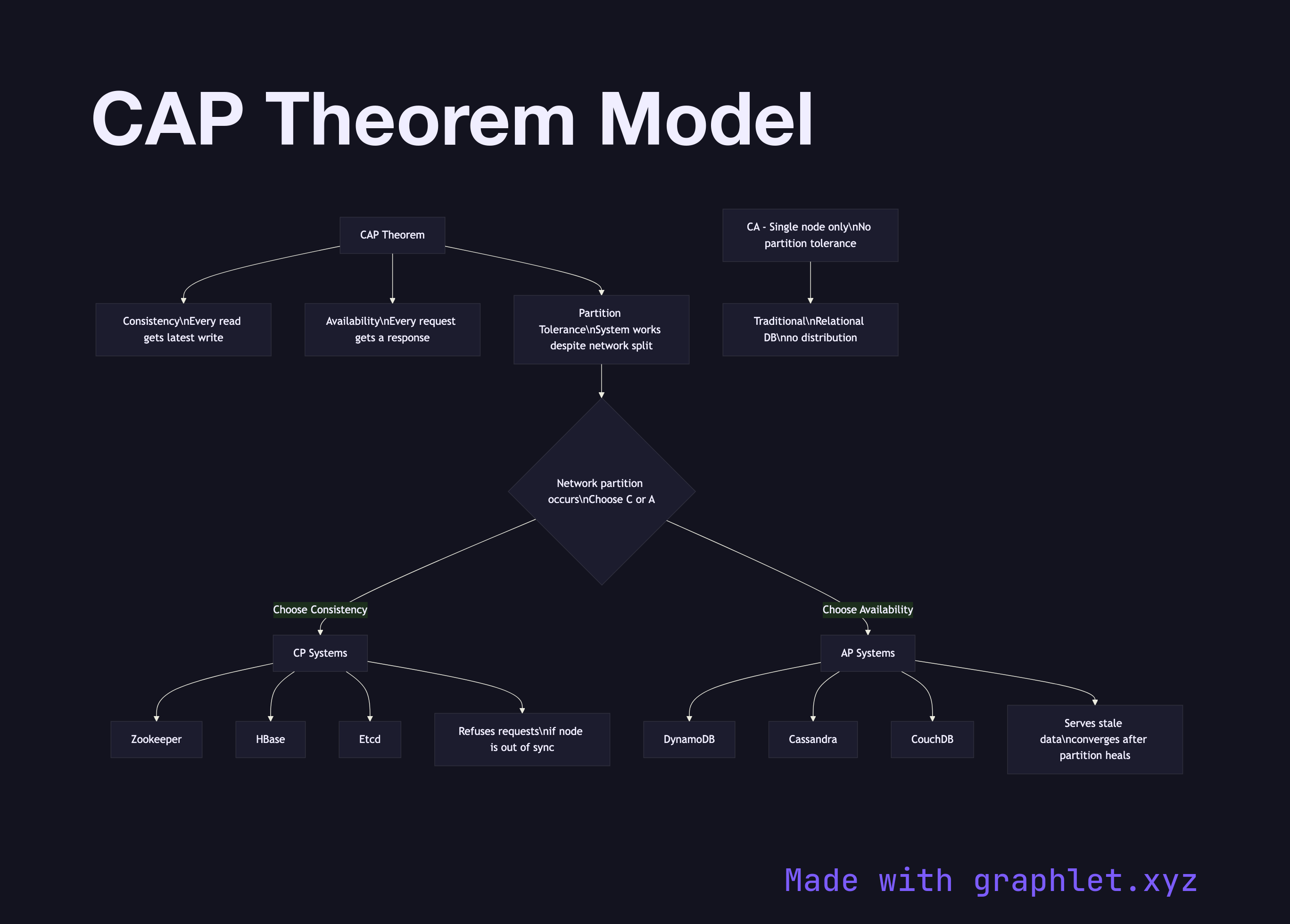
The CAP theorem states that a distributed data system can provide at most two of three properties simultaneously: Consistency, Availability, and Partition Tolerance — and that in the presence of a network partition, you must choose between consistency and availability.
This diagram maps the three CAP properties and shows where real systems fall when forced to make the trade-off during a network partition. Consistency (C) means every read receives the most recent write or an error — there are no stale reads. Availability (A) means every request receives a non-error response, though the data may not be the most recent. Partition Tolerance (P) means the system continues operating even when network partitions prevent some nodes from communicating.
Because network partitions are a physical reality in any distributed system, partition tolerance is effectively mandatory. The real choice is between C and A during a partition. A CP system (like Zookeeper, HBase, or a synchronously replicated PostgreSQL cluster) will refuse to serve reads or writes from a node that cannot confirm it has the latest data, sacrificing availability. A CA system is theoretical — it assumes no partitions and corresponds to a single-node relational database.
An AP system (like DynamoDB, Cassandra, or CouchDB) will continue serving reads and writes during a partition, accepting that different nodes may return different values. These systems implement Eventual Consistency to converge diverged state after the partition heals.
For developers, CAP determines the fundamental behavior contract of your database. If your application cannot tolerate stale reads, choose a CP database and design around potential unavailability during partition events. If uptime is paramount and you can handle stale data, an AP system with well-understood conflict resolution is appropriate.