High Availability System
A high availability (HA) system is designed to minimize downtime by eliminating single points of failure, using redundancy at every tier so that the failure of any single component does not cause a service outage.
A high availability (HA) system is designed to minimize downtime by eliminating single points of failure, using redundancy at every tier so that the failure of any single component does not cause a service outage.
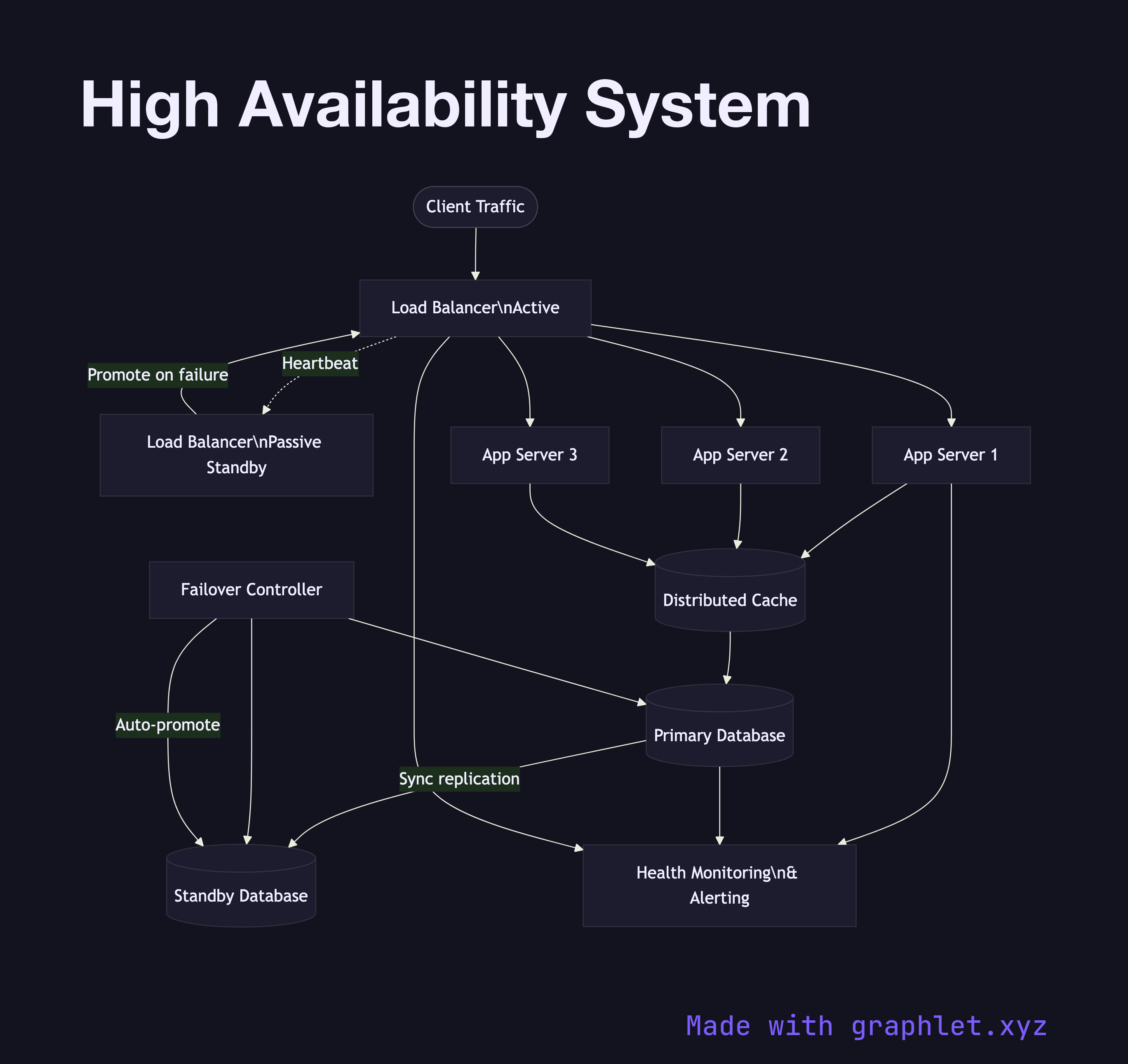
What the diagram shows
The diagram shows redundancy applied at each layer of the stack. Two Load Balancers operate in an active-passive configuration: the active LB handles all traffic while the passive LB monitors via a heartbeat and promotes itself if the active fails. Behind the load balancers, three Application Servers run in parallel; any two can fail and the service continues.
At the data tier, a Primary Database replicates synchronously to a Standby Database. A Failover Controller (e.g. Patroni, AWS RDS Multi-AZ) monitors both nodes and performs automatic promotion of the standby if the primary becomes unavailable. A shared Distributed Cache reduces database load. All health signals feed into a Health Monitoring system that triggers alerts and automated failover procedures.
Why this matters
High availability is typically expressed as a percentage uptime (99.9% = ~8.7 hours downtime/year; 99.99% = ~52 minutes/year). Each additional nine requires eliminating one more class of failure. The most impactful steps are: redundant load balancers, application server pools, and synchronous database replication with automated failover. For the cross-region extension of this pattern, see Multi Region Deployment. For the failover procedure in detail, see System Failover Architecture.