Data Replication Strategy
A data replication strategy defines how copies of data are maintained across multiple nodes in a distributed system, balancing the trade-offs between consistency (all replicas agree), durability (data survives failures), and performance (write and read latency).
A data replication strategy defines how copies of data are maintained across multiple nodes in a distributed system, balancing the trade-offs between consistency (all replicas agree), durability (data survives failures), and performance (write and read latency).
Replication is fundamental to fault tolerance: if one node fails, another holds a copy. But replication immediately raises the consistency question — what happens when a write reaches some replicas but not others before a failure?
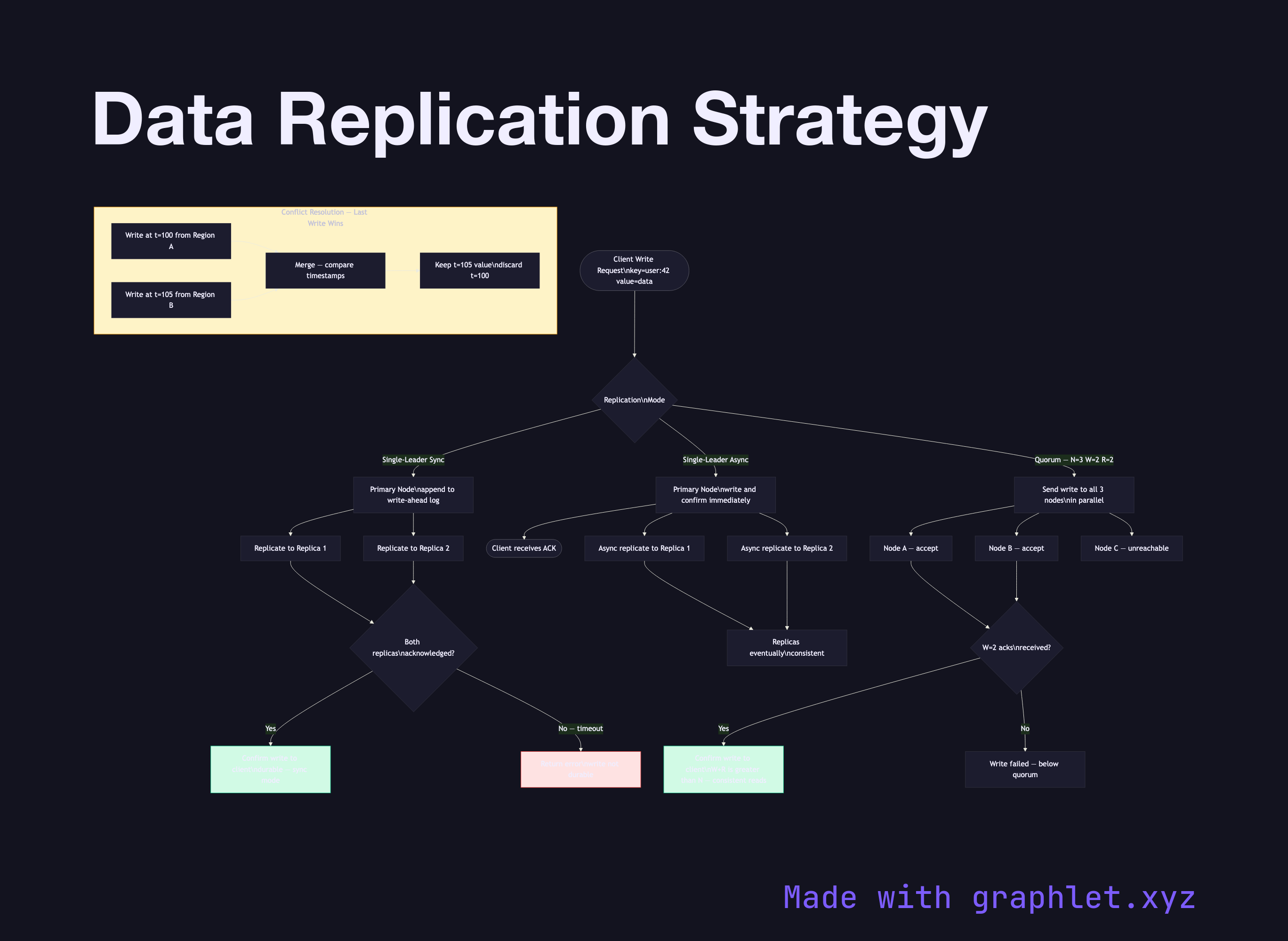
Single-Leader Replication (Primary-Replica): All writes go to a designated primary node, which applies the write and forwards it to replicas. Reads can be served by any replica (risking stale reads) or only by the primary (consistent reads). MySQL's binlog replication, PostgreSQL's streaming replication, and Kafka's ISR model follow this pattern. See Raft Consensus Algorithm for how the leader position is maintained durably.
Synchronous vs. Asynchronous Replication: In synchronous mode, the primary waits for acknowledgment from a quorum (or all) replicas before confirming the write to the client. This guarantees durability but adds write latency proportional to the slowest replica. Asynchronous replication confirms immediately and replicates in the background — lower latency but risk of data loss on primary failure.
Quorum Writes and Reads: Systems like Cassandra, DynamoDB, and Riak let operators configure W (write quorum) and R (read quorum). The rule W + R > N (where N is replication factor) guarantees that at least one node in every read quorum has the latest write. Common settings: N=3, W=2, R=2.
Conflict Resolution: When network partitions allow two primaries to accept writes (split-brain), conflicts arise. Resolution strategies include last-write-wins (timestamp ordering), vector clocks (Riak, Dynamo), CRDTs (conflict-free replicated data types), or explicit application-level merges. The Cluster Coordination Architecture shows how distributed locks and fencing tokens prevent split-brain in strict consistency systems.