Database Replication
Database replication is the process of copying and maintaining the same data across multiple database servers so that every node reflects a consistent (or eventually consistent) view of the dataset.
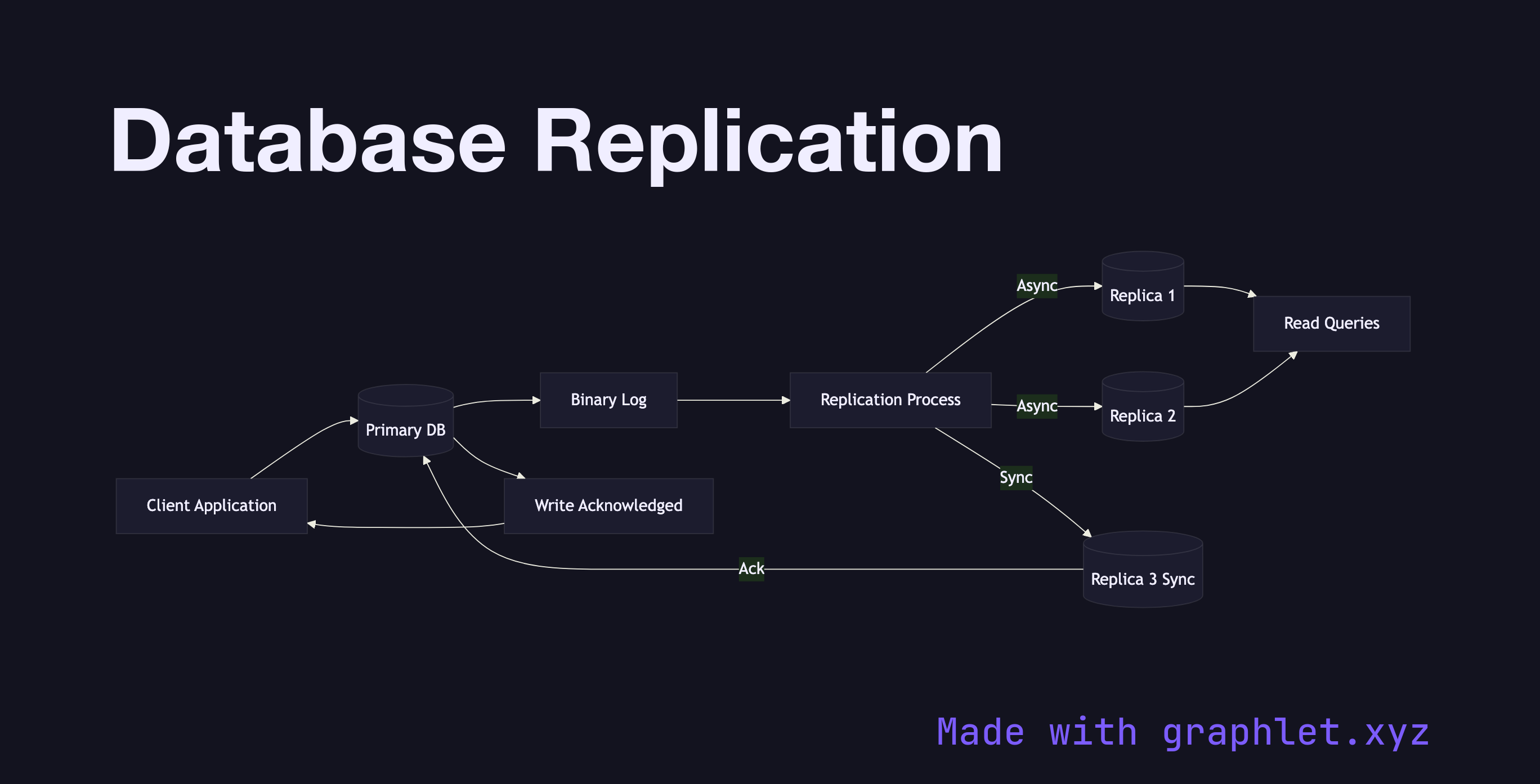
Database replication is the process of copying and maintaining the same data across multiple database servers so that every node reflects a consistent (or eventually consistent) view of the dataset.
This diagram shows the topology of a standard replication setup. A single Primary node accepts all write operations. Every INSERT, UPDATE, and DELETE is recorded in a binary log (or write-ahead log, depending on the engine). The replication process reads those log entries and forwards them to one or more Replica nodes, which apply the changes to their own storage in the same order.
The diagram distinguishes between synchronous and asynchronous replication paths. In synchronous mode the primary waits for at least one replica to confirm the write before acknowledging success to the client — this guarantees zero data loss on failover but increases write latency. In asynchronous mode the primary acknowledges immediately; replicas catch up in the background. This is the default in MySQL and PostgreSQL streaming replication. The trade-off is a replication lag window during which the replica's data is stale.
Replicas typically serve read traffic only. Routing reads to replicas reduces load on the primary and allows horizontal read scaling. The Read Write Splitting diagram shows how application-layer proxies or drivers implement this routing. When the primary fails, one replica must be promoted — the Database Failover diagram traces that promotion sequence in detail.
For developers, replication is the starting point for any high-availability database architecture. However, reading from replicas means accepting that data may be milliseconds to seconds behind the primary. Applications that require read-your-writes consistency must either route those reads to the primary or implement session-level stickiness. The Primary Replica Sync diagram shows the precise message exchange that drives log shipping between nodes.