Connection Pooling
Connection pooling is the practice of maintaining a cache of open database connections that can be reused across multiple application requests, eliminating the overhead of establishing a new TCP connection and authenticating on every query.
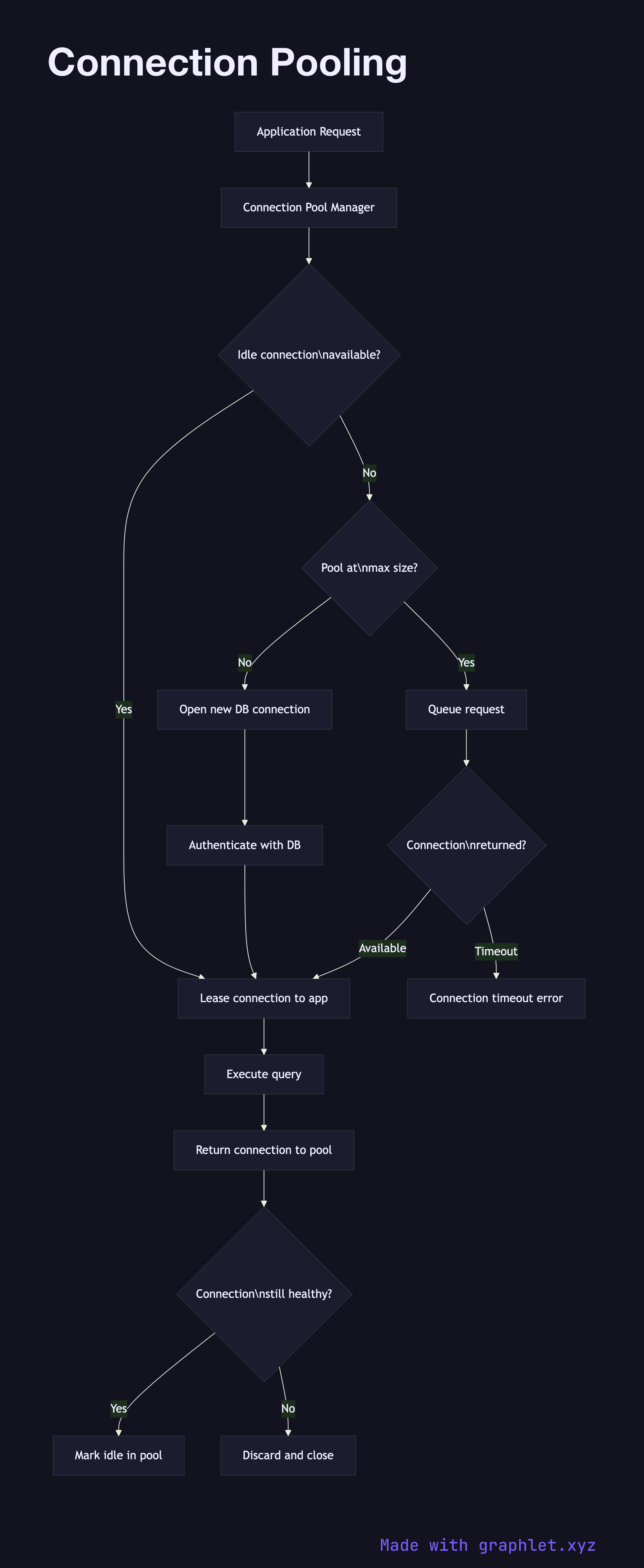
Connection pooling is the practice of maintaining a cache of open database connections that can be reused across multiple application requests, eliminating the overhead of establishing a new TCP connection and authenticating on every query.
This diagram shows the lifecycle of a connection request through a pool. The application requests a connection from the pool manager (implemented by tools like PgBouncer, HikariCP, or pgpool-II). The pool manager checks its pool of idle connections. If one is available, it is immediately leased to the application. If not, and the pool has not reached its configured maximum size, a new physical connection is established to the database and handed over. If the pool is at capacity, the request queues until a connection is returned.
When the application finishes its query or transaction, it returns the connection to the pool rather than closing it. The pool manager marks it idle and makes it available for the next requester. Periodically, the pool validates connections in the idle queue by issuing a lightweight keepalive query to discard any that were closed by the database server due to inactivity timeouts.
The performance benefit is dramatic. Opening a PostgreSQL connection involves TCP handshake, TLS negotiation, and authentication — this can take 20–100ms. With pooling, connection acquisition drops to sub-millisecond. For a service handling thousands of requests per second this is the difference between a responsive system and one that saturates the database's max_connections limit.
Pooling is critical in conjunction with Read Write Splitting, where a proxy maintains separate pools for primary and replica connections. In Database Sharding architectures, each shard requires its own pool, multiplying the number of managed connections significantly. Pool sizing — minimum, maximum, and checkout timeout — requires careful tuning based on observed query duration and connection acquisition latency.