Database Sharding
Database sharding is a horizontal scaling technique that partitions a dataset across multiple independent database instances — called shards — so that each node holds only a subset of the total data.
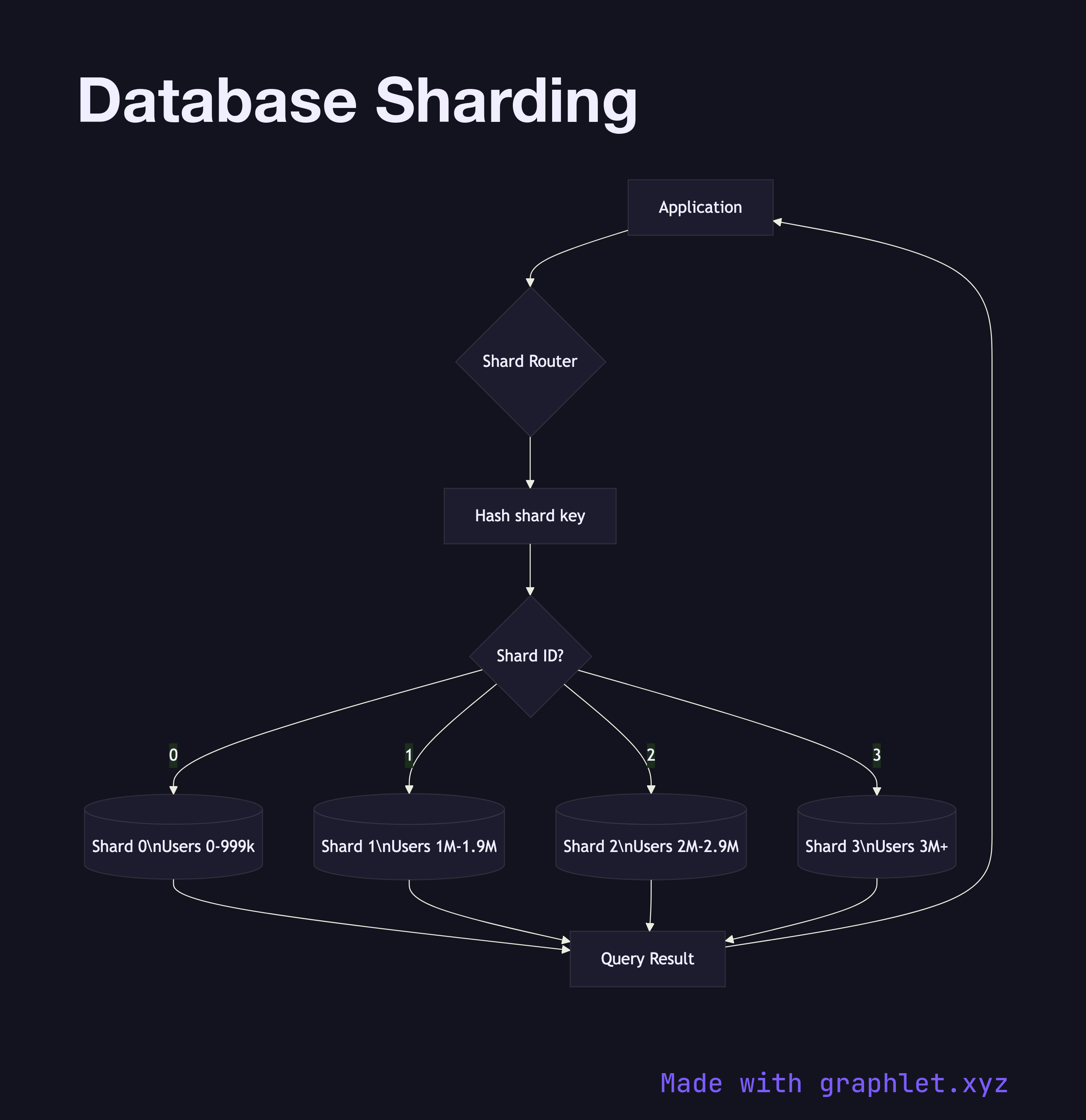
Database sharding is a horizontal scaling technique that partitions a dataset across multiple independent database instances — called shards — so that each node holds only a subset of the total data.
This diagram shows how a shard router (sometimes called a proxy or query router) sits between the application and the database tier. When the application issues a query, the router inspects the shard key — a field chosen to distribute rows evenly, such as user ID or tenant ID. A hash function or range map translates the key value into a shard ID, which identifies which physical database node owns the data for that key.
Each shard is a fully independent database instance. Shard 1 might hold user IDs 1–1,000,000, Shard 2 holds 1,000,001–2,000,000, and so on for range-based sharding. In consistent hash sharding, the key is hashed into a ring and each node owns an arc of the ring. Both approaches aim to minimize hot spots — situations where a disproportionate share of traffic lands on one shard.
Sharding solves write throughput limits that replication alone cannot address: no matter how many replicas you add, all writes still funnel through one primary. Sharding splits the write load across N primaries. The cost is cross-shard queries: joins, aggregations, or transactions that span shard boundaries require scatter-gather execution at the router layer, which is slow and complex.
Sharding is often paired with per-shard replication. Each shard primary has its own set of replicas for read scaling and failover. This combination is visible in the Database Replication diagram. For lighter-weight partitioning within a single instance, see Partitioned Table Architecture. At the application level, Connection Pooling manages the increased number of database connections that a sharded architecture requires.