Read Write Splitting
Read-write splitting is a database routing pattern that directs write operations to the primary node and read operations to one or more replica nodes, allowing read traffic to scale independently of write capacity.
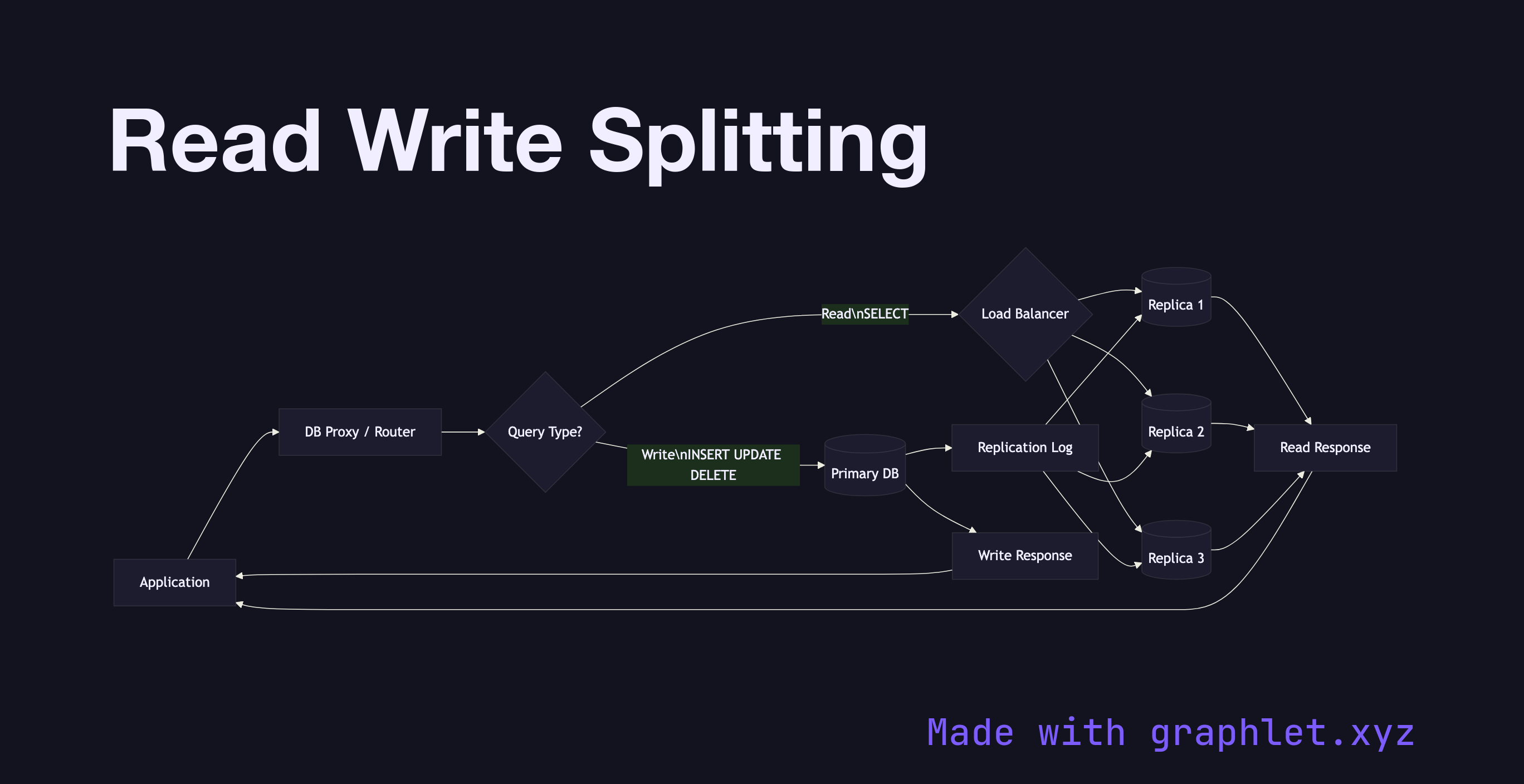
Read-write splitting is a database routing pattern that directs write operations to the primary node and read operations to one or more replica nodes, allowing read traffic to scale independently of write capacity.
This diagram shows the routing logic implemented by a proxy layer — tools like ProxySQL, PgBouncer, or an application-level ORM plugin. The proxy inspects each incoming query. If it is a write (INSERT, UPDATE, DELETE, DDL), the proxy forwards it to the primary. If it is a read (SELECT), the proxy distributes it across available replicas using a load-balancing algorithm such as round-robin or least-connections.
The primary handles all writes and then replicates changes to replicas via the mechanism shown in Primary Replica Sync. Replicas serve read queries using slightly stale data — the degree of staleness depends on replication lag, which is a function of write volume and network latency.
The practical impact is significant: in most OLTP workloads reads outnumber writes 10:1 or higher. By moving reads to replicas you can scale read throughput by simply adding more replica nodes without touching the primary. This is far cheaper than vertical scaling and avoids the complexity of Database Sharding.
There are two important consistency caveats. First, a client that writes a record and immediately reads it may hit a replica that hasn't yet applied the update — a read-your-writes violation. Applications must either route post-write reads to the primary for a brief window or use sticky sessions. Second, transactions must execute entirely on the primary, since replicas are read-only. The Connection Pooling diagram shows how poolers manage the underlying connections to both primary and replica pools.