Database Migration Workflow
A database migration workflow is the controlled process of applying schema or data changes to a production database — adding columns, creating indexes, renaming tables, backfilling data — in a way that is safe, reversible, and minimally disruptive to running applications.
A database migration workflow is the controlled process of applying schema or data changes to a production database — adding columns, creating indexes, renaming tables, backfilling data — in a way that is safe, reversible, and minimally disruptive to running applications.
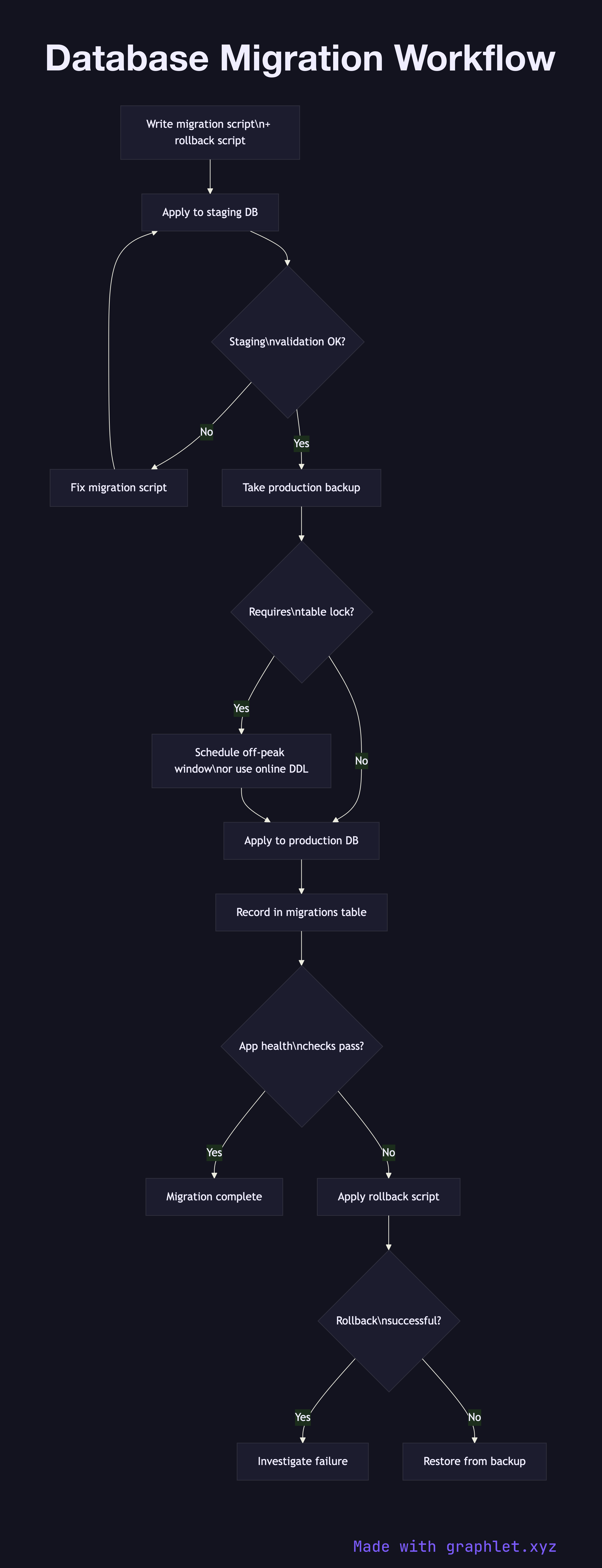
This diagram shows the recommended migration workflow used in production environments. The process begins with writing the migration script and its corresponding rollback script, then running it against a staging environment that mirrors production data size and schema as closely as possible. A staging validation step checks that the migration completes in an acceptable time window, produces the correct schema diff, and does not break any application queries.
Before touching production, a backup is taken to ensure a recovery point exists. The backup step is non-negotiable: even well-tested migrations can have unexpected effects on large tables. See Backup and Restore Flow for the mechanics of that process.
In production, large schema changes (adding a non-null column, building an index on a multi-million row table) must be executed in a way that does not hold a full table lock for minutes. PostgreSQL's CREATE INDEX CONCURRENTLY and MySQL's online DDL are designed for this. The migration tool (Flyway, Liquibase, Alembic, or custom scripts) records each applied migration in a migrations table, preventing double-application.
After the migration runs, a health check validates that application metrics, query latencies, and error rates are normal. If any anomaly is detected, the rollback script is applied. The workflow enforces the principle that every migration must be forward and backward compatible with the currently deployed application code — which is why the expand-contract pattern (add new column, migrate data, drop old column across separate deployments) is preferred over a single big-bang migration.