Database Failover
Database failover is the automatic (or manual) process of promoting a replica to become the new primary when the original primary node becomes unavailable, restoring write availability with minimal downtime.
Database failover is the automatic (or manual) process of promoting a replica to become the new primary when the original primary node becomes unavailable, restoring write availability with minimal downtime.
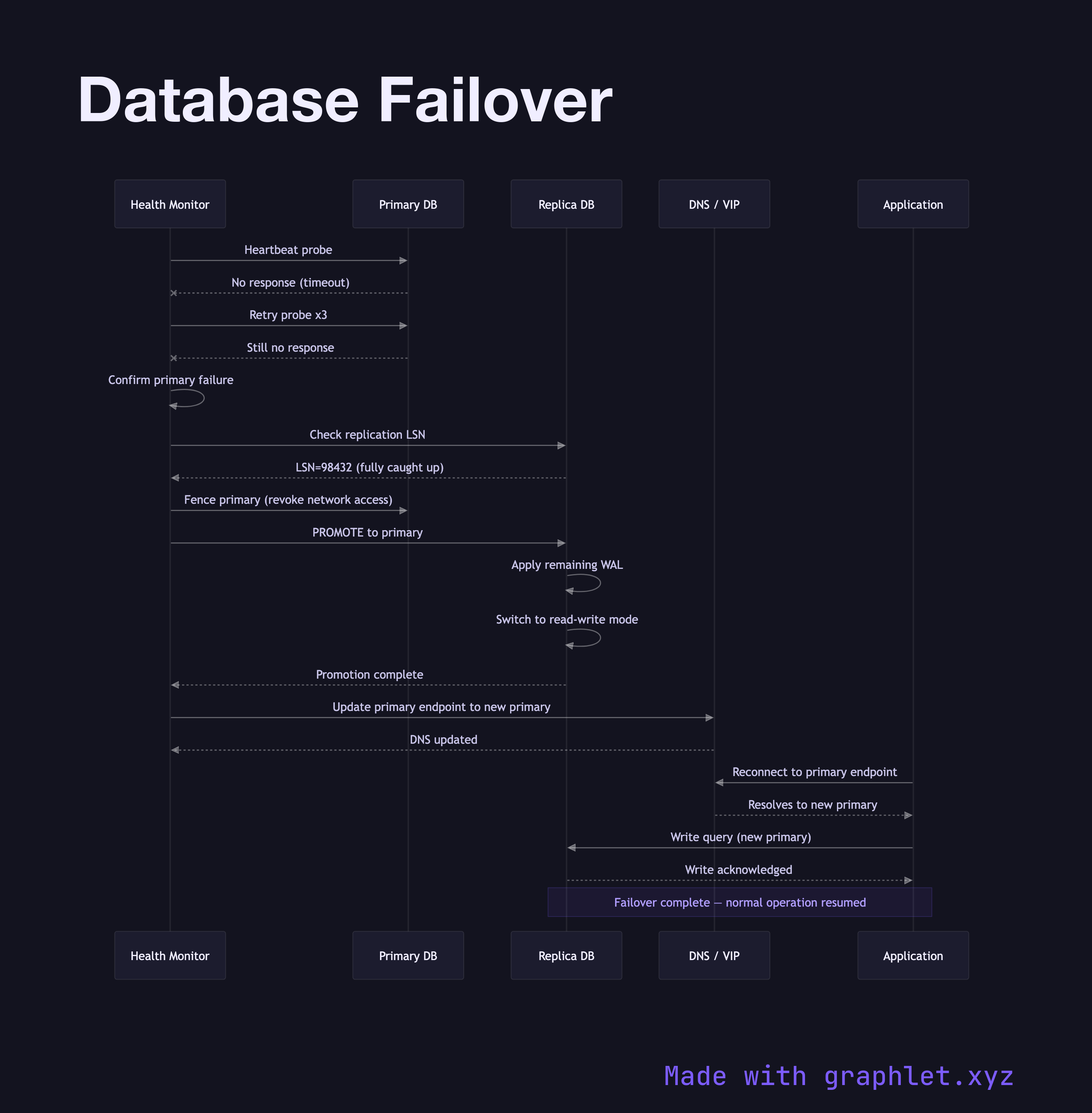
This sequence diagram traces the events from the moment the primary stops responding through to the point where the application is routing writes to the new primary. The health monitor (typically a tool like Patroni, Orchestrator, AWS RDS Multi-AZ, or a Kubernetes operator) continuously sends heartbeat probes to the primary. When the primary fails to respond within a configured timeout, the monitor starts a failure confirmation round — checking multiple times from multiple vantage points to avoid a false positive caused by a transient network hiccup.
Once failure is confirmed, the monitor identifies the most advanced replica — the one with the highest applied log sequence number (LSN), meaning it has the least data loss. In a synchronous replication setup the synchronous standby is always fully caught up and is the natural choice.
The monitor issues a PROMOTE command to the chosen replica. The replica completes applying any remaining WAL from its standby queue, then transitions to primary mode: it begins accepting write connections and stops consuming replication messages. The old primary is fenced — its network access is revoked or its process is killed — to prevent a split-brain scenario where two nodes both believe they are the primary.
Finally, the DNS record or virtual IP for the primary endpoint is updated to point to the new primary. The application's Connection Pooling layer detects the connection failure, reconnects to the endpoint, and resumes normal operation. Total failover time in well-configured systems ranges from 10 to 60 seconds.