Stream Processing Pipeline
A stream processing pipeline is an architecture that continuously ingests, transforms, enriches, and routes high-throughput event data in real time, enabling decisions and outputs with latency measured in milliseconds rather than hours.
A stream processing pipeline is an architecture that continuously ingests, transforms, enriches, and routes high-throughput event data in real time, enabling decisions and outputs with latency measured in milliseconds rather than hours.
Traditional batch processing collects data, waits for a window to close, then runs a bulk computation. Stream processing eliminates the wait: each event is processed as it arrives, enabling use cases like real-time fraud detection, live leaderboards, dynamic pricing, and operational dashboards.
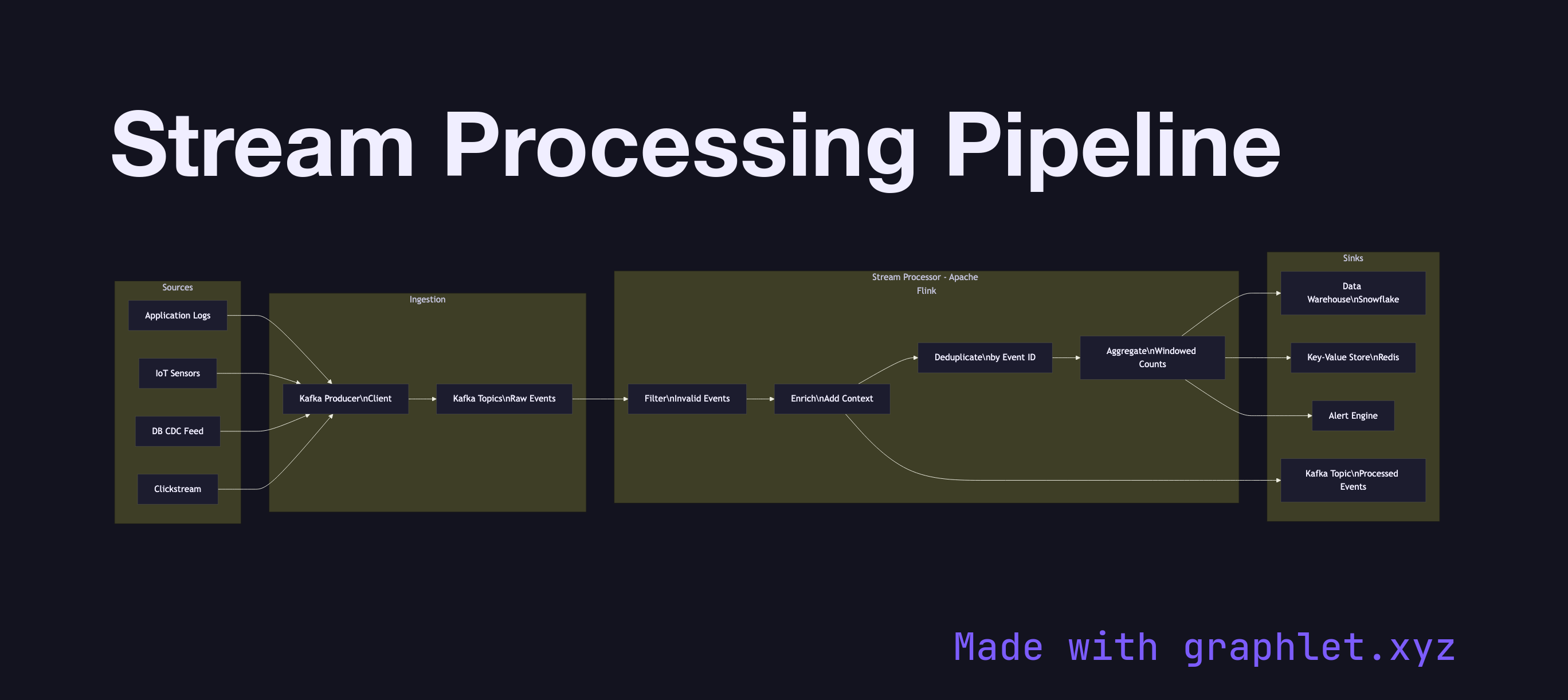
A pipeline has three logical stages. The ingestion layer accepts events from producers — application logs, IoT sensors, user click streams, database CDC feeds — and writes them to a durable event log (typically Kafka). Ingestion is designed for high throughput and low latency, often batching small messages to amortize network overhead.
The processing layer reads from the event log and applies stateless or stateful transformations. Stateless operations — filtering, mapping, format conversion — are simple: each event is transformed independently. Stateful operations — aggregations, joins across streams, sessionization — require the processor to maintain state, which introduces checkpointing for fault tolerance. Frameworks like Kafka Streams, Apache Flink, and Apache Spark Structured Streaming manage this complexity, including exactly-once processing guarantees tied to Exactly Once Delivery semantics.
The sink layer routes processed results to their destinations: a data warehouse for historical analysis, a key-value store for real-time lookups, a downstream Kafka topic for further processing, or a monitoring system for alerting. Message Deduplication at the sink prevents duplicate writes when processors retry after failures. The full architecture sits within the broader Event Streaming Architecture pattern.