Edge Computing Architecture
Edge computing is a distributed computing paradigm that moves data processing and application logic physically closer to the source of data — IoT devices, mobile users, or branch offices — reducing latency, bandwidth consumption, and dependence on centralized cloud data centers.
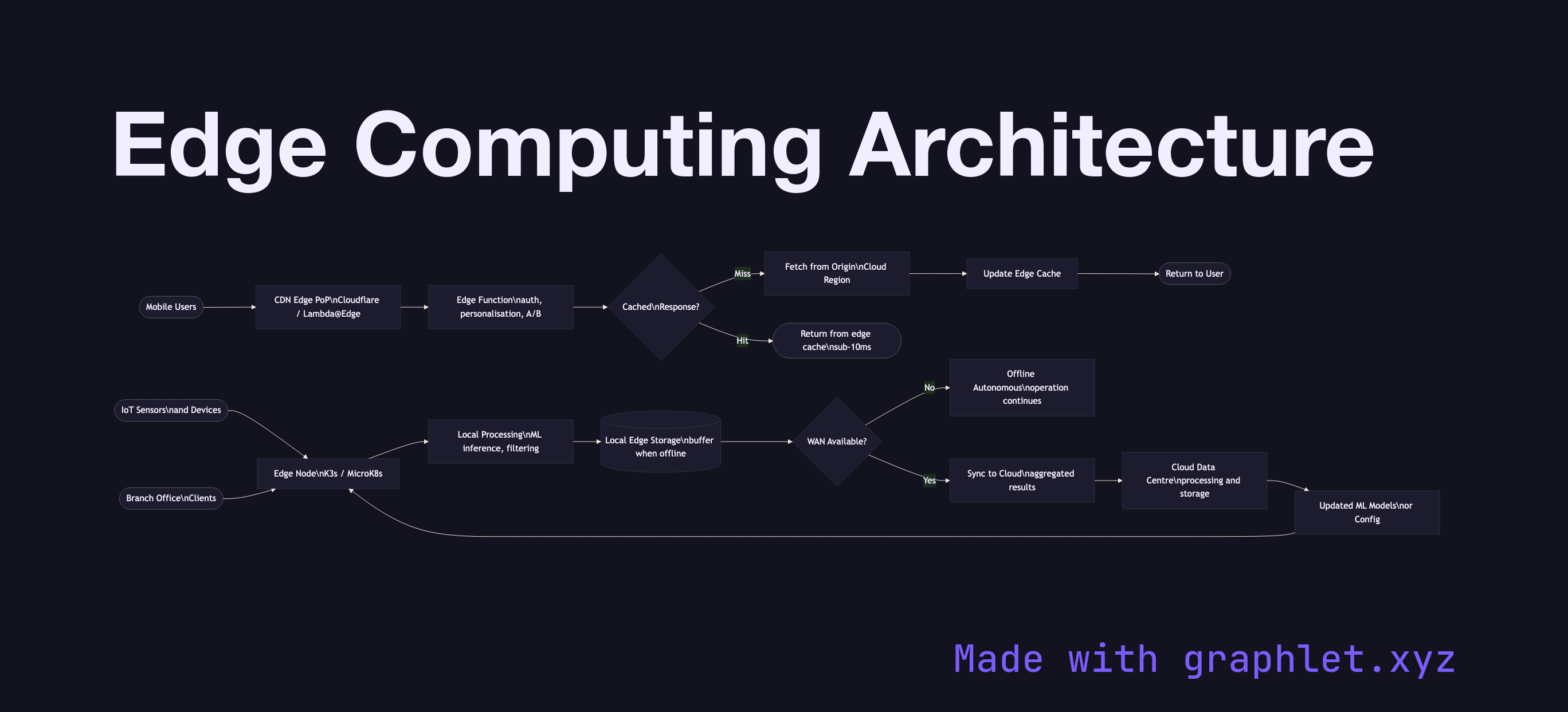
Edge computing is a distributed computing paradigm that moves data processing and application logic physically closer to the source of data — IoT devices, mobile users, or branch offices — reducing latency, bandwidth consumption, and dependence on centralized cloud data centers.
In a traditional cloud architecture, every request travels to a central cloud region potentially hundreds of milliseconds away. For latency-sensitive applications — real-time gaming, video processing, industrial IoT, augmented reality — this round-trip is unacceptable. Edge computing inserts a processing tier at the network edge: within CDN Points of Presence, carrier infrastructure, on-premise edge servers, or on the device itself.
CDN edge functions (Cloudflare Workers, AWS Lambda@Edge, Fastly Compute@Edge) run application code at CDN PoPs worldwide. They can personalize responses, perform A/B testing, handle authentication, and rewrite requests — all without a round-trip to the origin. Response times drop from 200ms to under 10ms.
Industrial edge nodes in factory or retail environments run containerized workloads locally (Kubernetes distributions like K3s or MicroK8s). They process sensor data, run ML inference for quality control or anomaly detection, and act autonomously when the WAN link to the cloud is unavailable — syncing results when connectivity is restored.
Edge-cloud sync replicates processed results, aggregated metrics, and model updates between edge and cloud. The cloud remains the system of record and the source of updated ML models and configuration.
See CDN Edge Caching for how static content is served from edge nodes, and Cloud Monitoring Pipeline for aggregating telemetry from edge locations.