Kubernetes Scheduler
The Kubernetes scheduler is the control plane component responsible for assigning newly created pods to nodes — selecting the best node based on resource availability, constraints, affinity rules, and custom scoring policies.
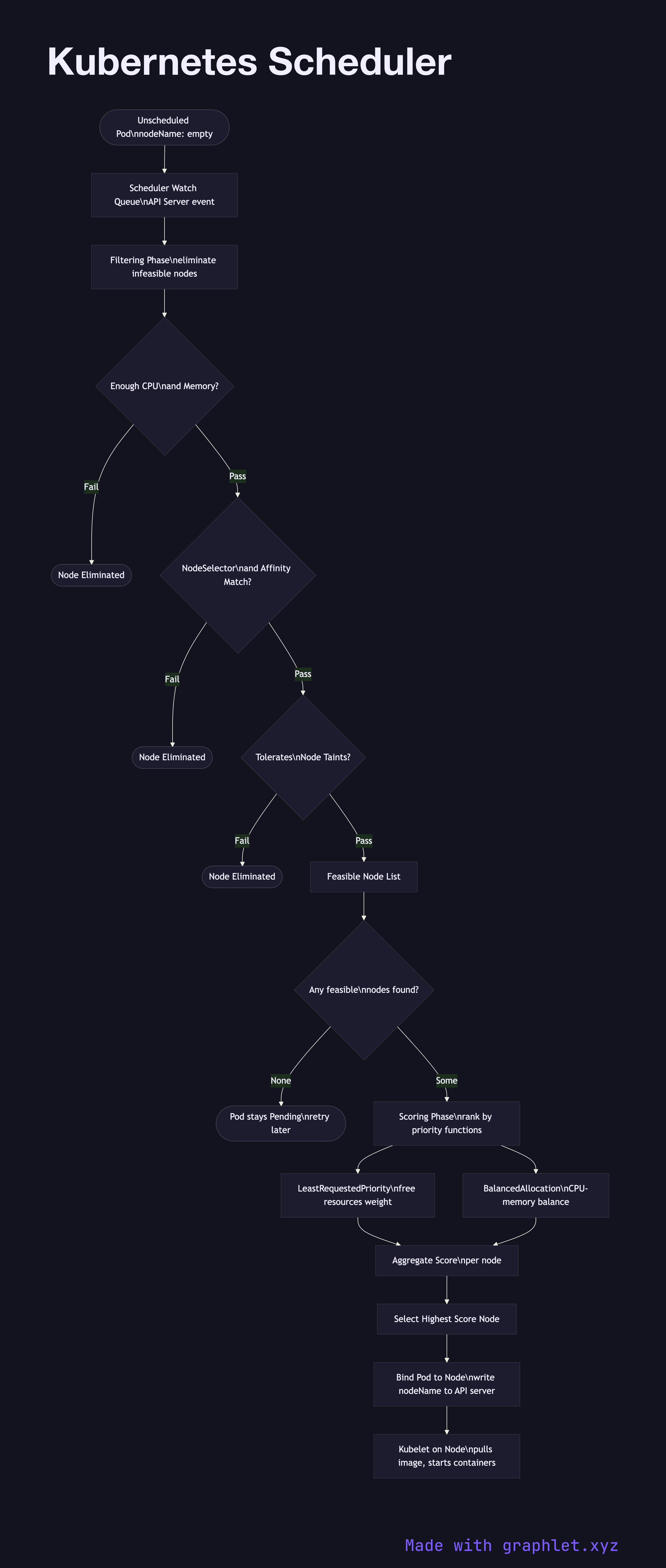
The Kubernetes scheduler is the control plane component responsible for assigning newly created pods to nodes — selecting the best node based on resource availability, constraints, affinity rules, and custom scoring policies.
When a pod is created without a nodeName field, it enters the Pending state with no node assignment. The scheduler watches for unscheduled pods via the API server and processes them through a two-phase pipeline:
Phase 1 — Filtering eliminates nodes that cannot run the pod. Hard constraints evaluated include: - Resource fit: Does the node have enough unallocated CPU and memory for the pod's requests? - NodeSelector / nodeAffinity: Does the node carry the required labels? - Taints and tolerations: Does the pod tolerate any taints on the node? - PodAffinity / PodAntiAffinity: Should this pod be co-located with or kept away from other pods? - Volume constraints: Can the node access required PersistentVolumes?
Nodes failing any filter are eliminated. If no nodes pass, the pod remains Pending until cluster capacity changes (e.g., auto-scaling adds a node).
Phase 2 — Scoring ranks the filtered candidates. Default scoring functions include: LeastRequestedPriority (prefer nodes with more free resources), BalancedResourceAllocation (avoid CPU/memory skew), NodeAffinityPriority (weight preferred affinities). The node with the highest aggregate score wins.
The scheduler then binds the pod to the winning node by writing the nodeName into the pod spec via the API server. The kubelet on that node picks up the binding and starts pulling images and creating containers.
See Kubernetes Pod Lifecycle for what happens after binding, and Auto Scaling Workflow for how new nodes become available when the scheduler finds no feasible candidates.