Kubernetes Pod Lifecycle
The Kubernetes pod lifecycle describes the set of states a pod passes through from the moment it is created until it terminates — including the conditions and events that cause transitions between states.
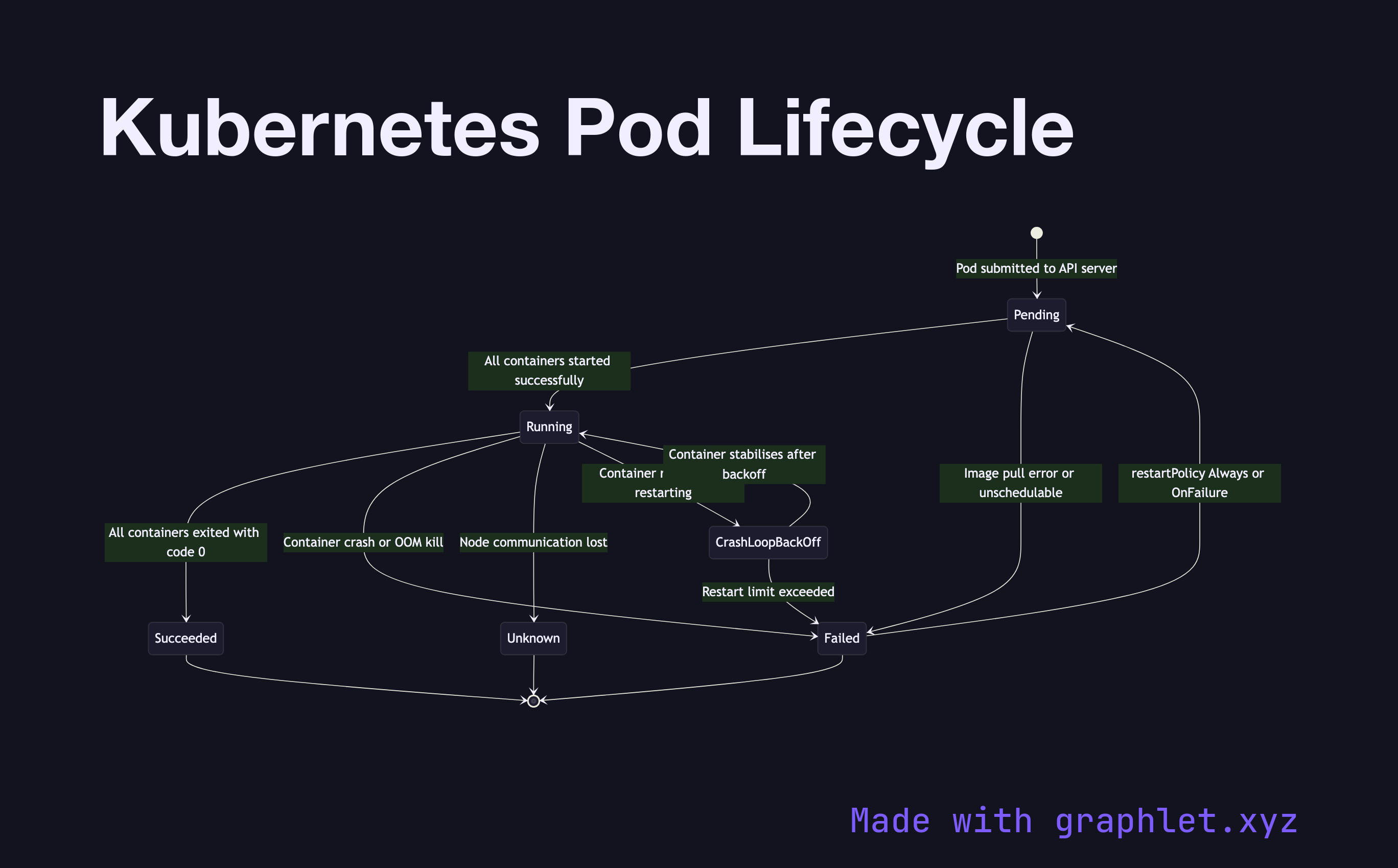
The Kubernetes pod lifecycle describes the set of states a pod passes through from the moment it is created until it terminates — including the conditions and events that cause transitions between states.
When a pod is submitted to the API server, it enters the Pending state. In this state, the scheduler has not yet assigned the pod to a node, or the node has accepted the pod but containers haven't started — usually because images are being pulled. Pending can be prolonged by resource constraints (no node has enough CPU/memory), missing PersistentVolumeClaims, or unresolvable node selectors.
Once all containers in the pod have started successfully, the pod enters Running. Running means at least one container is still executing. From Running, three outcomes are possible:
- Succeeded: All containers exited with code 0 (success). This is the terminal state for batch jobs. - Failed: At least one container exited with a non-zero code, or was OOM-killed by the kernel. Depending on the restartPolicy, Kubernetes may restart containers with exponential backoff (CrashLoopBackOff). - Unknown: The control plane lost communication with the node hosting the pod, typically due to a node crash or network partition.
The CrashLoopBackOff condition (visible in kubectl get pods) is not a top-level phase but an indication that a container in a Running pod is repeatedly crashing. The backoff timer resets after 5 minutes of successful running.
Understanding pod phases is essential when debugging deployments and interpreting Container Deployment Pipeline rollout behavior. See Kubernetes Scheduler for how pods move from Pending to assigned, and Kubernetes Service Routing for how Running pods receive traffic.