Raft Consensus Algorithm
Raft is a distributed consensus algorithm designed to be more understandable than Paxos, providing a mechanism for a cluster of nodes to agree on a sequence of values even when some nodes fail or become unreachable.
Raft is a distributed consensus algorithm designed to be more understandable than Paxos, providing a mechanism for a cluster of nodes to agree on a sequence of values even when some nodes fail or become unreachable.
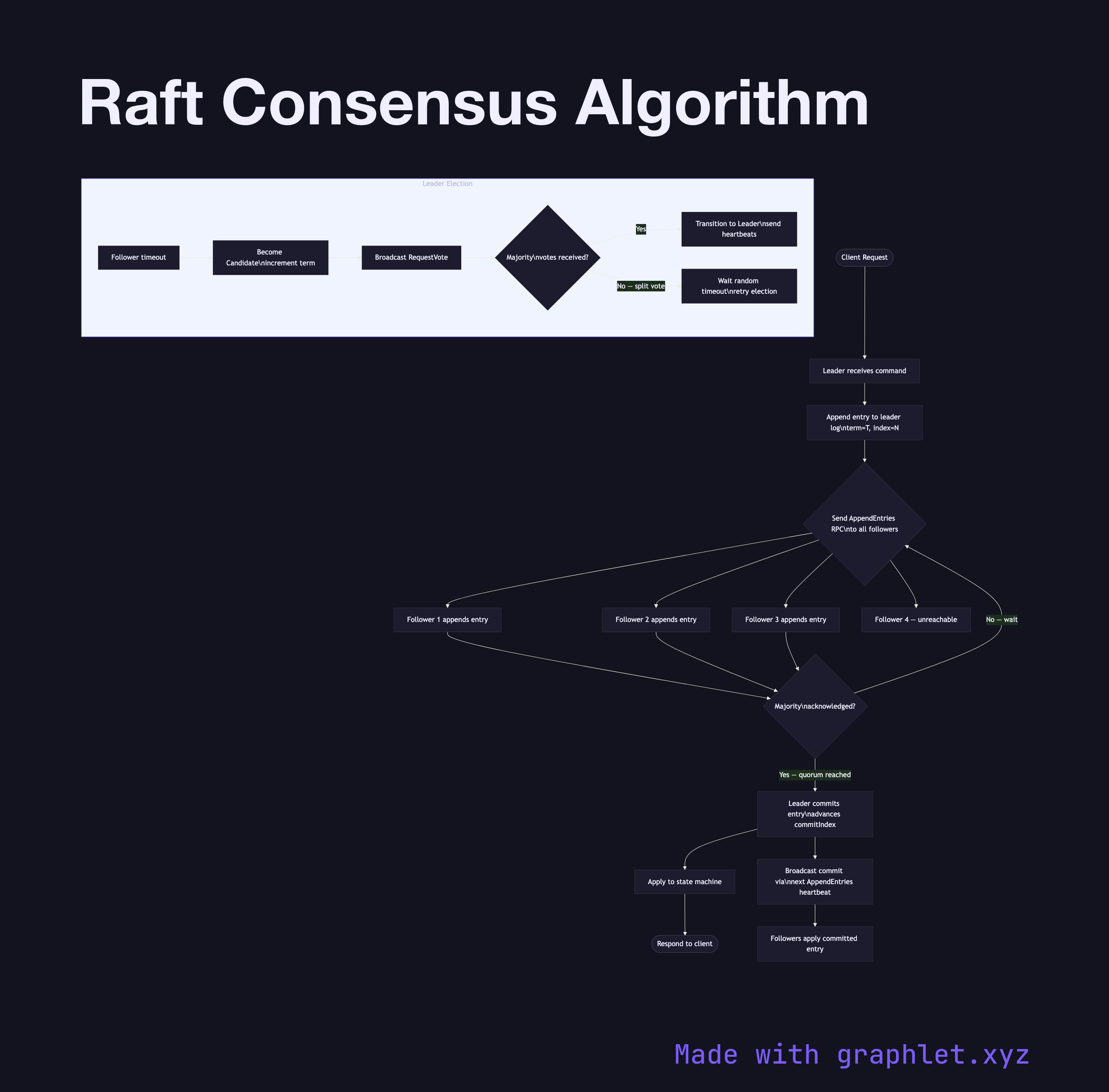
Raft divides the consensus problem into three relatively independent sub-problems: leader election, log replication, and safety. At any given time, each node is in one of three states: Follower, Candidate, or Leader. Under normal operation a single Leader exists, followers passively replicate entries, and the cluster processes client requests entirely through the Leader.
Leader Election occurs when a follower's election timeout fires without receiving a heartbeat from a leader. The follower increments its current term, transitions to Candidate, votes for itself, and broadcasts RequestVote RPCs to all peers. A candidate becomes leader once it receives votes from a majority of nodes. Raft's randomized election timeouts (150–300 ms) reduce split-vote situations. See Leader Election Algorithm for the sequence-level detail.
Log Replication is the core of Raft. The leader appends the client's command to its own log, then sends AppendEntries RPCs in parallel to all followers. Once a majority acknowledges the entry, the leader commits the entry, advances its commit index, and applies the command to the state machine. Followers commit after they see the leader's updated commit index in the next heartbeat.
Safety is ensured by Raft's election restriction: a candidate cannot win unless its log is at least as up-to-date as a majority of nodes. "Up-to-date" is determined first by term number, then by log length. This guarantees that every committed entry appears in the log of any future leader, preventing data loss across elections.
Raft is the algorithm behind etcd, CockroachDB, TiKV, and Consul's leader subsystem. Compare it with Paxos Consensus Flow to understand why Raft's explicit leader model simplifies implementation. Cluster membership changes are handled by Raft's joint consensus or single-server change approaches, described alongside the broader Cluster Coordination Architecture.