Cluster Coordination Architecture
Cluster coordination architecture describes the set of services and protocols that allow multiple nodes in a distributed system to agree on shared state — including cluster membership, configuration, distributed locks, and leader identity — providing a consistent foundation for higher-level applications.
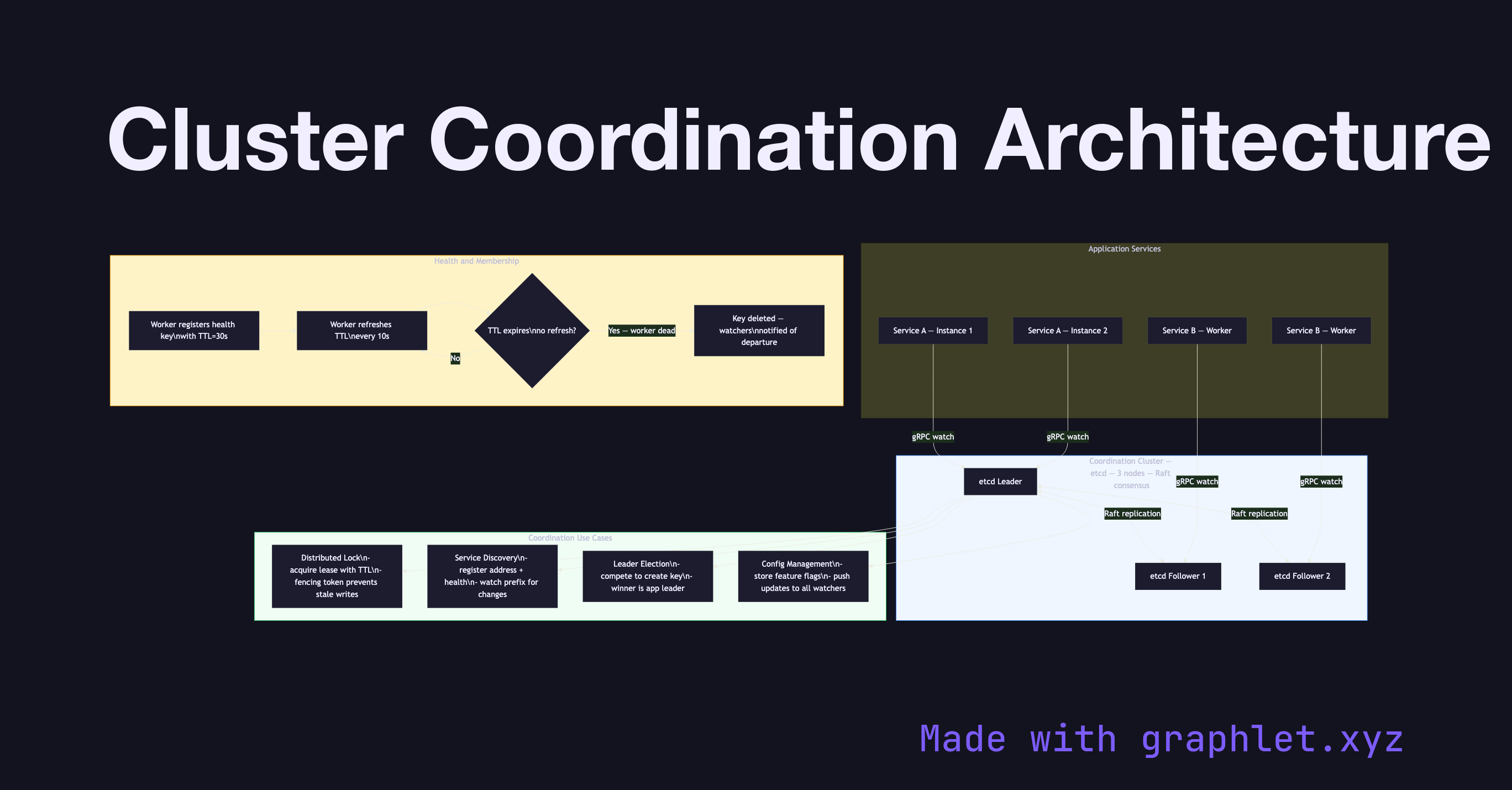
Cluster coordination architecture describes the set of services and protocols that allow multiple nodes in a distributed system to agree on shared state — including cluster membership, configuration, distributed locks, and leader identity — providing a consistent foundation for higher-level applications.
Coordination is hard because it requires strong consistency in the face of network partitions and node failures. Systems that need cluster coordination typically rely on a dedicated coordination service (ZooKeeper, etcd, Consul) backed by a consensus algorithm like Raft to guarantee linearizability.
Coordination Service: The coordination service (e.g., etcd) runs as a small cluster of 3 or 5 nodes. Its own internal consensus guarantees that writes are durable and reads are linearizable. Application services talk to this cluster through a client library, watching keys for changes with low-latency push notifications.
Distributed Locking: Services that need mutual exclusion (e.g., only one instance should run a migration at a time) acquire a lease from the coordination service. The lease is associated with a time-to-live (TTL); if the holder crashes, the lock expires automatically. A fencing token (monotonically increasing version number) prevents a slow lock holder from corrupting data after the lease expires. See Distributed Locking for the full protocol.
Service Discovery and Configuration: Workers register their address and health status in the coordination service. Clients watch these registrations and update their routing tables when workers join or leave. Global configuration values (feature flags, rate limits) are also stored here, enabling zero-downtime configuration changes pushed to all instances simultaneously.
Leader Election in Applications: Application-level leader election (distinct from the coordination service's internal election) is implemented by multiple instances competing to create the same key with a TTL. The instance that creates the key first wins; others watch the key and take over if it disappears. Compare with Leader Election Algorithm for the lower-level Raft-based mechanism.