Message Queue Retry
Message queue retry is a reliability pattern in which a failed message is re-enqueued for reprocessing after a delay, with the attempt count tracked to eventually route persistently failing messages to a dead letter queue.
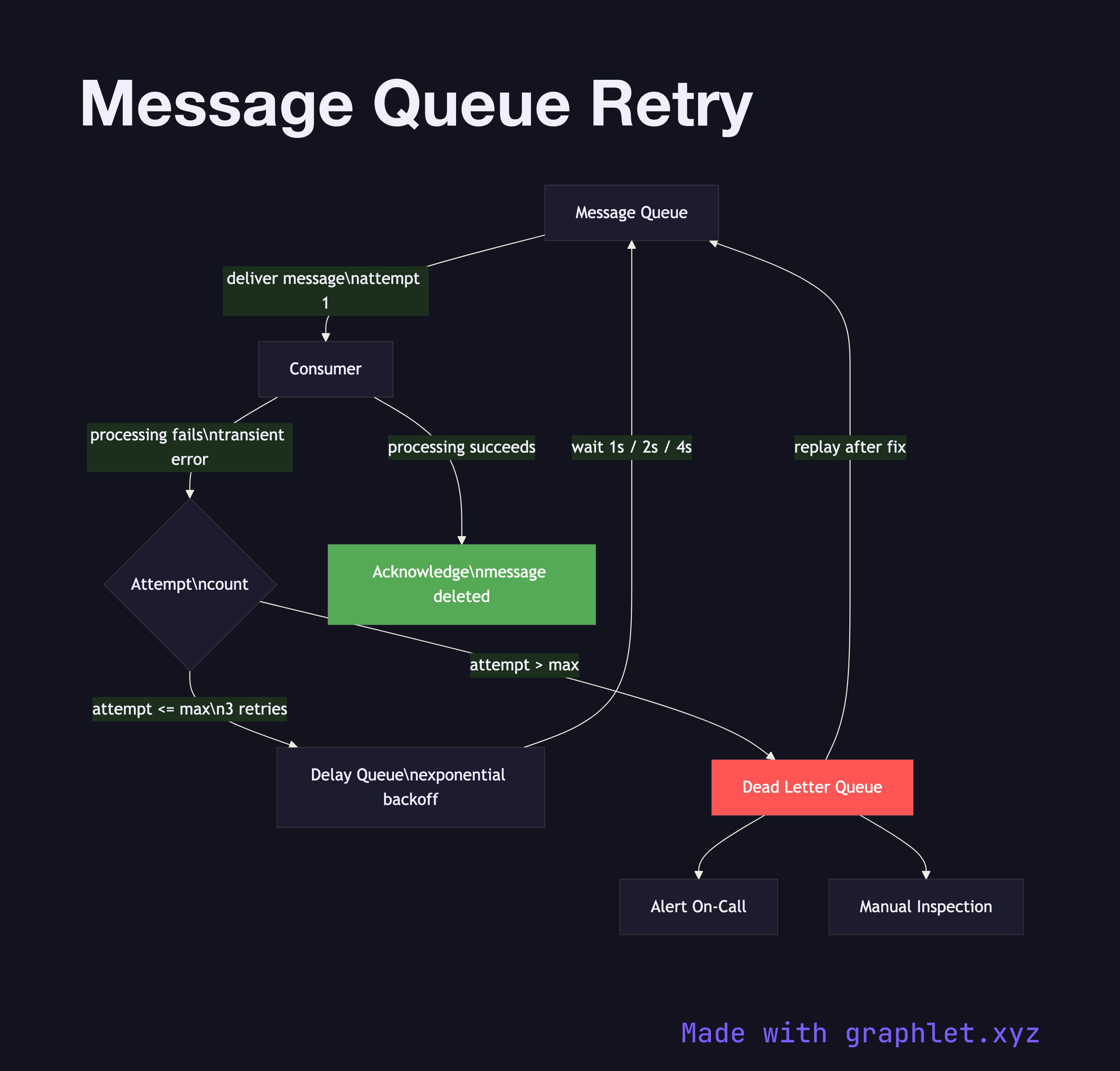
Message queue retry is a reliability pattern in which a failed message is re-enqueued for reprocessing after a delay, with the attempt count tracked to eventually route persistently failing messages to a dead letter queue.
Transient failures are a fact of life in distributed systems: a downstream API returns a 503, a database connection times out, or a downstream service restarts during a deployment. Without a retry strategy, a single transient error causes permanent message loss. Queue-level retry addresses this without requiring the producer to resend.
The pattern works by attaching metadata to each message: a delivery count (or attempt count) and optionally a next-visible-at timestamp. When a consumer fails to process a message (either by throwing an exception or by not acking within the visibility timeout), the queue makes the message visible again after a backoff delay. Exponential backoff — doubling the wait time on each retry — is the standard approach: 1s, 2s, 4s, 8s. This prevents a storm of retries from overwhelming an already-struggling downstream service.
Each retry increments the attempt counter. When the counter exceeds the configured maximum (typically 3–5), the message is not re-queued into the main queue but instead forwarded to a Dead Letter Queue for inspection, alerting, or manual replay. This prevents a poison message from blocking the queue indefinitely.
Retry logic pairs directly with Idempotent Consumer design: because a message may be delivered and processed multiple times, consumers must produce the same outcome regardless of how many times they receive the same message. This is the foundation of safe at-least-once delivery semantics, explored further in Exactly Once Delivery.