Consensus Algorithm
A consensus algorithm enables a cluster of distributed nodes to agree on a single value or sequence of values despite network partitions and node failures — the fundamental building block for replicated state machines, distributed databases, and coordination services.
A consensus algorithm enables a cluster of distributed nodes to agree on a single value or sequence of values despite network partitions and node failures — the fundamental building block for replicated state machines, distributed databases, and coordination services.
What the diagram shows
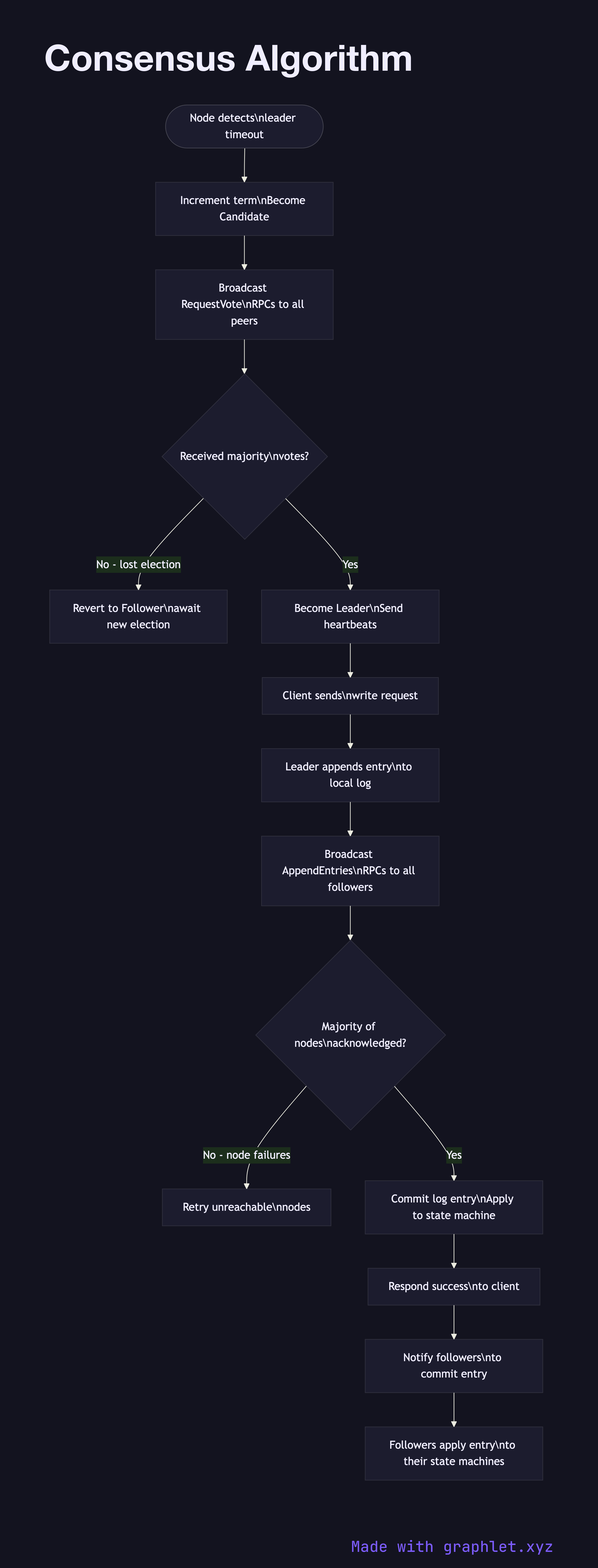
The diagram models the Raft consensus algorithm's core flow across a 5-node cluster. The flow begins with Leader Election: if no leader exists or a heartbeat timeout fires, a node increments its term and transitions to Candidate, broadcasting RequestVote RPCs to all peers. Nodes that haven't voted in this term cast a vote; a candidate that receives votes from a majority (3 of 5) becomes the new Leader.
Once elected, the Leader processes client writes via the Log Replication phase: it appends the new entry to its own log, sends AppendEntries RPCs to all followers in parallel, and waits for a majority acknowledgment. When the majority confirms, the entry is committed and the Leader applies it to the state machine and responds to the client. Followers apply committed entries in order, maintaining identical state machine replicas.
Why this matters
Consensus is hard because you must handle the intersection of concurrency, partial failure, and network unreliability. Raft was designed to be more understandable than Paxos by partitioning the problem into leader election, log replication, and safety — each with well-defined invariants. Any system that claims strong consistency (etcd, CockroachDB, TiKV, Consul) uses a consensus algorithm under the hood. For leader election as a standalone use case, see Leader Election. For the locking primitive built on top of consensus stores, see Distributed Locking.