Leader Election
Leader election is the process by which nodes in a distributed cluster collectively agree on a single node to act as the coordinator — the leader — responsible for making decisions, distributing work, and maintaining cluster-wide state.
Leader election is the process by which nodes in a distributed cluster collectively agree on a single node to act as the coordinator — the leader — responsible for making decisions, distributing work, and maintaining cluster-wide state.
What the diagram shows
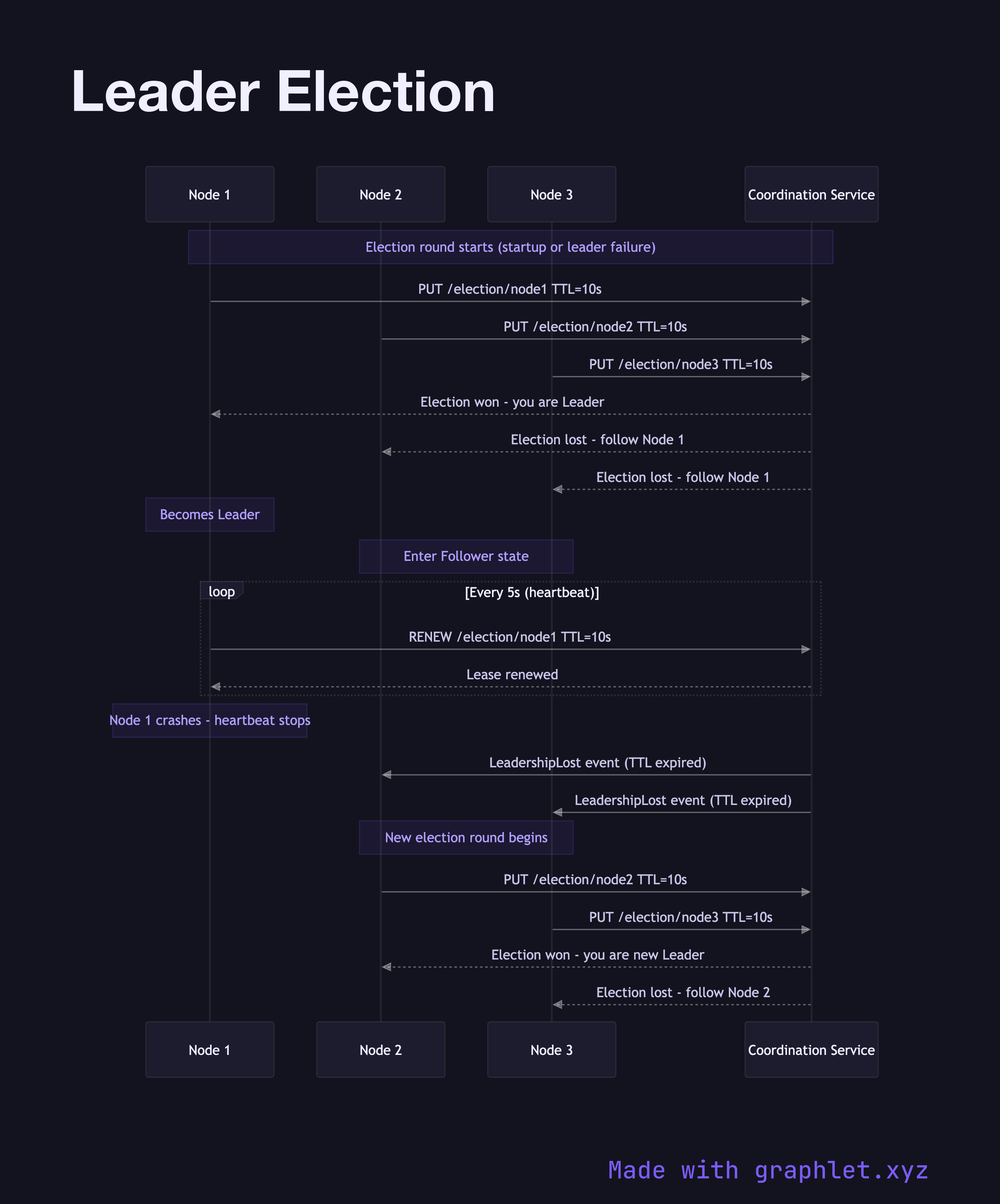
This sequence diagram models leader election using a consensus-based approach (similar to etcd/Raft or ZooKeeper). Three nodes — Node 1, Node 2, and Node 3 — and a Coordination Service participate. On startup or after detecting that the previous leader has failed, each node sends a PUT /election/{nodeId} request with a TTL to the Coordination Service, attempting to write to the same key. The Coordination Service applies first-writer-wins semantics: Node 1 wins the election and receives a confirmation. Node 2 and Node 3 receive "election lost" responses.
Node 1, now the Leader, begins sending periodic heartbeat renewals to keep the election key from expiring. Node 2 and Node 3 enter Follower state, subscribing to the leader key via a watch. When the leader's heartbeat stops (crash or network partition), the TTL expires, the key is deleted, and the Coordination Service broadcasts a LeadershipLost event. The remaining nodes immediately start a new election round.
Why this matters
Leader election is foundational to any distributed system that requires a single authoritative coordinator — distributed job schedulers, database primary selection, and shard assignment all depend on it. The two failure modes to guard against are split-brain (two nodes both believe they are leader) and the election storm (nodes spin in tight election loops during instability). Using a TTL-based lease with a coordination service provides strong consistency guarantees that prevent split-brain. For the locking primitive that uses a similar mechanism, see Distributed Locking.