Distributed Locking
Distributed locking is a coordination mechanism that ensures only one node in a cluster can access a shared resource or execute a critical section at any given time, preventing race conditions that would corrupt shared state.
Distributed locking is a coordination mechanism that ensures only one node in a cluster can access a shared resource or execute a critical section at any given time, preventing race conditions that would corrupt shared state.
What the diagram shows
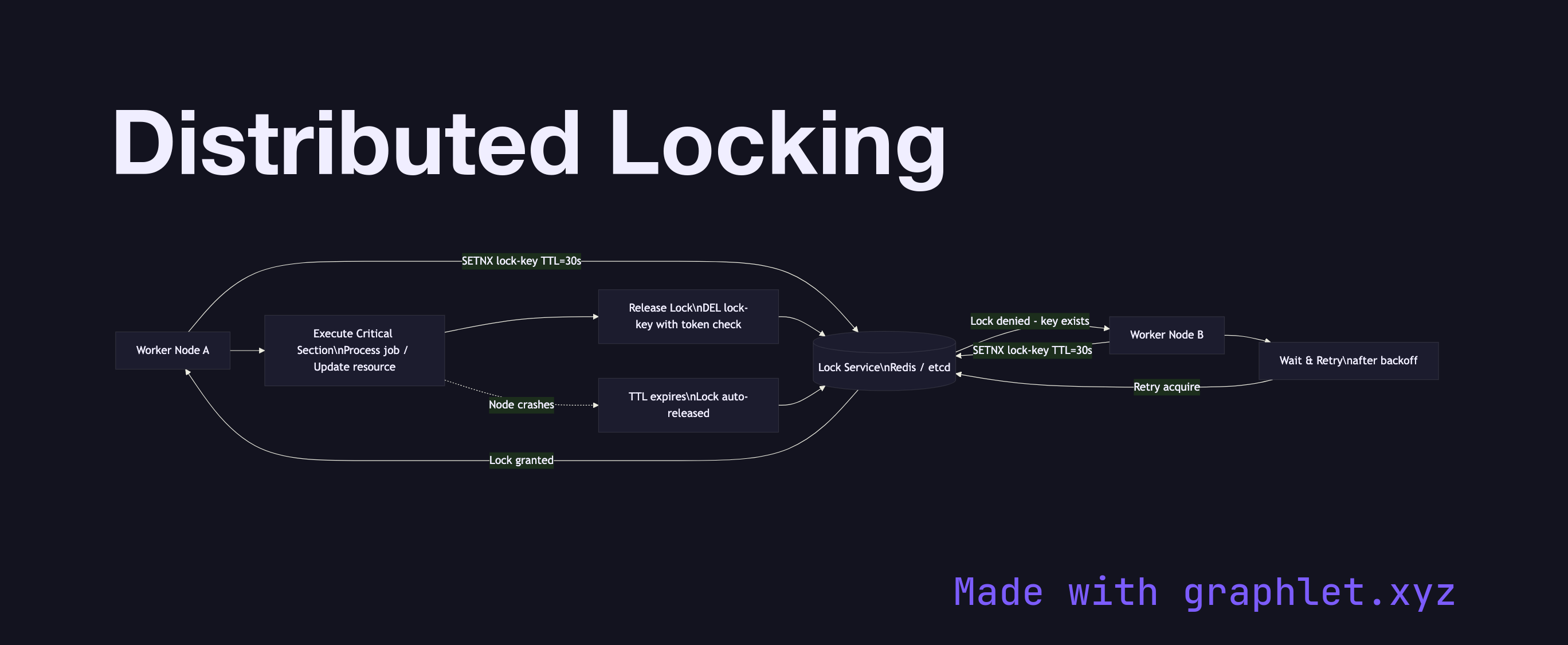
The diagram shows two competing Worker Nodes (Node A and Node B) both attempting to acquire a lock from a Lock Service (typically Redis with the Redlock algorithm, ZooKeeper, or etcd). Node A sends an SETNX (set if not exists) command with a lock key and a TTL. The Lock Service grants the lock to Node A and returns success; Node B's concurrent attempt receives a failure response because the key already exists.
Node A proceeds to execute the Critical Section — for example, processing a job or updating a shared counter. Upon completion, Node A explicitly releases the lock by deleting the key (using a Lua script to ensure it only deletes its own lock token, not one acquired by a different node after TTL expiry). If Node A crashes mid-execution, the TTL ensures the lock expires automatically, preventing deadlock.
Why this matters
Distributed locking solves the "thundering herd" problem in job processing — without it, multiple workers may pick up the same job from a queue and process it multiple times, causing duplicate side effects. The critical subtleties are lock TTL tuning (too short and a slow job loses the lock; too long and a crashed node blocks progress) and fencing tokens (monotonically increasing IDs that let downstream systems reject requests from a node that lost its lock). For leader election — a closely related primitive — see Leader Election.