Distributed System Overview
A distributed system is a collection of independent computers that appear to users as a single coherent system, coordinating their work by passing messages over a network.
A distributed system is a collection of independent computers that appear to users as a single coherent system, coordinating their work by passing messages over a network.
What the diagram shows
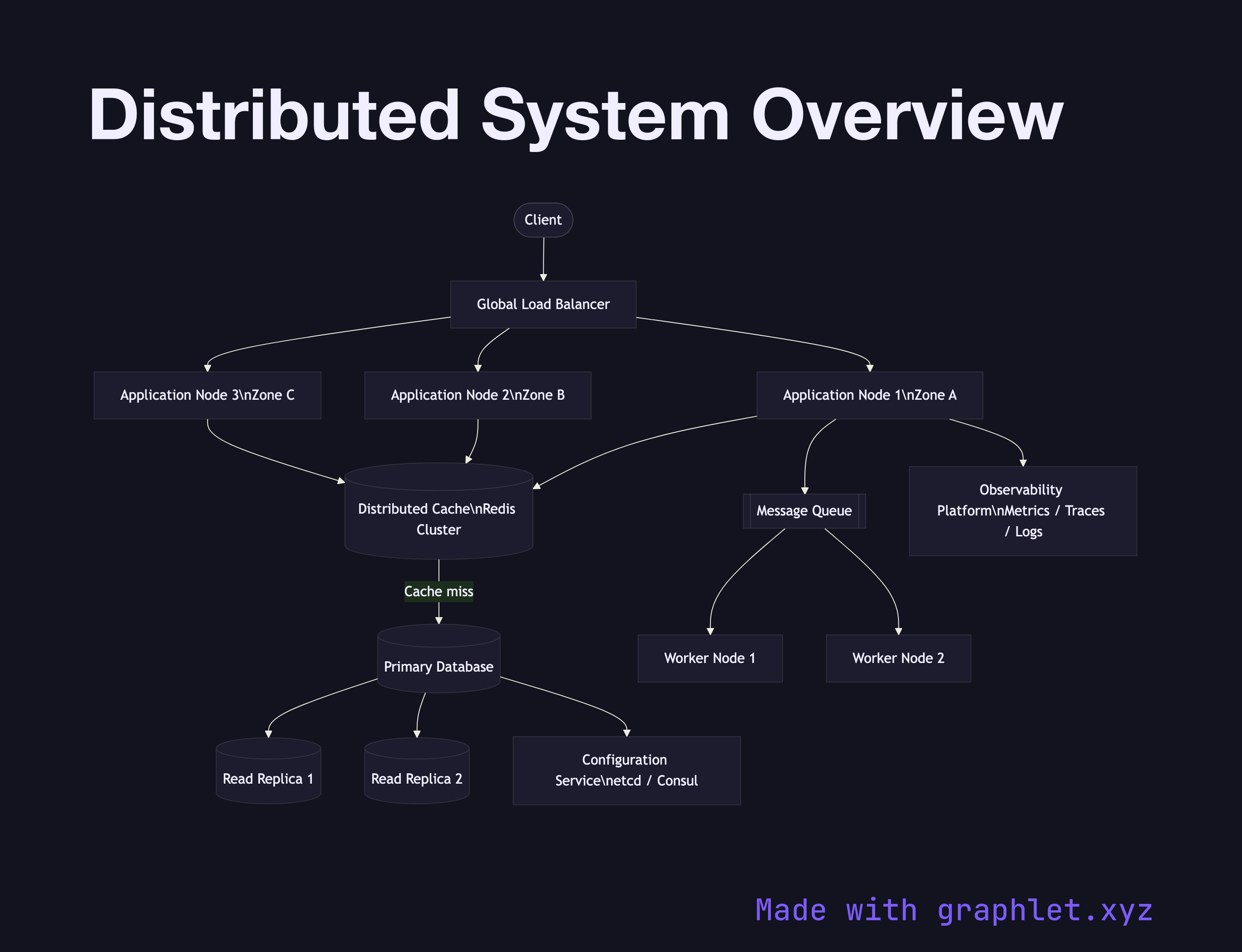
The diagram presents a bird's-eye view of the key tiers in a typical distributed system. External clients reach the system through a Global Load Balancer, which routes traffic to one of several Application Nodes running across multiple availability zones. The application tier reads from a Distributed Cache (e.g. Redis Cluster) before falling back to the Primary Database. Write-heavy paths go directly to the primary, while reads can be served from Read Replicas to horizontally scale query throughput.
Asynchronous workloads are offloaded to a Message Queue, consumed by Worker Nodes that process jobs in the background. All nodes ship logs and metrics to a central Observability Platform for tracing, alerting, and dashboarding. A Configuration Service (e.g. etcd, Consul) provides distributed coordination for leader election, feature flags, and runtime configuration.
Why this matters
Understanding the full system topology — load balancing, caching, replication, queuing, and coordination — lets engineers make informed trade-offs at each layer. For example, adding a read replica reduces database load but introduces replication lag; caching speeds reads but requires invalidation strategies. This overview diagram is the starting point for discussing those trade-offs with your team.
Explore individual components in depth: Distributed Cache, Distributed Locking, High Availability System, and Distributed Tracing Flow.