Distributed Cache
A distributed cache is a caching layer spread across multiple nodes that stores frequently accessed data in memory, reducing latency and database load by serving reads from RAM rather than disk — with consistent hashing to distribute keys evenly across the cluster.
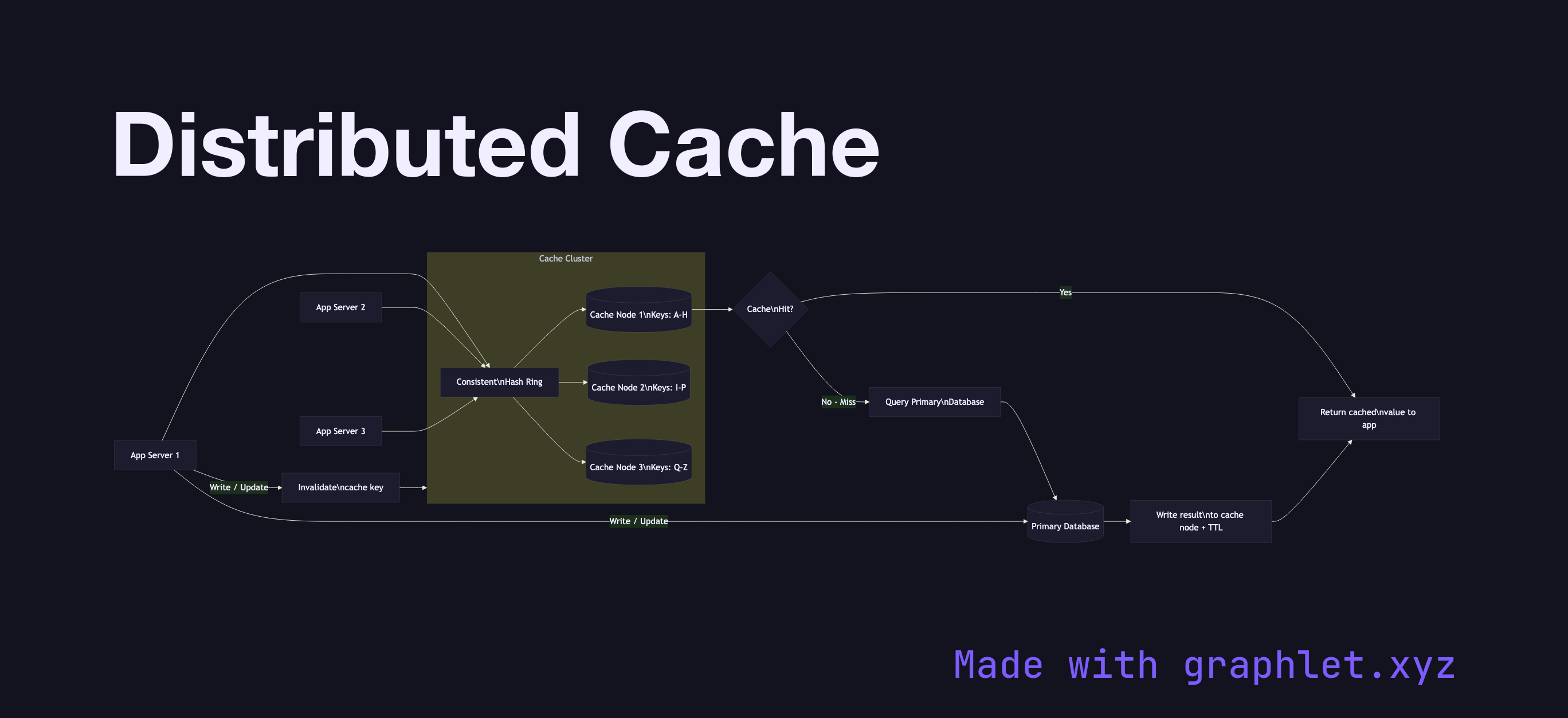
A distributed cache is a caching layer spread across multiple nodes that stores frequently accessed data in memory, reducing latency and database load by serving reads from RAM rather than disk — with consistent hashing to distribute keys evenly across the cluster.
What the diagram shows
The diagram shows multiple Application Servers all connecting to a Cache Cluster composed of three nodes (Cache Node 1, Cache Node 2, Cache Node 3). Consistent hashing (handled by a client-side library or a proxy like Twemproxy) routes each key to the correct node deterministically, so all application servers independently resolve the same node for the same key.
The read path uses Cache-Aside (lazy loading): the application checks the cache first. On a cache hit, the value is returned directly. On a cache miss, the application queries the Primary Database, writes the result into the appropriate cache node with a TTL, and returns the value to the caller. Writes go directly to the database and invalidate the corresponding cache key to prevent stale reads.
Why this matters
Distributed caches like Redis Cluster or Memcached dramatically reduce database load for read-heavy workloads. A cache hit at 0.5ms versus a database query at 5–50ms represents a 10–100x latency improvement for hot data. Sizing the cluster correctly requires estimating working set size (not total data, just hot data) and eviction policies. Cache invalidation — knowing when to expire or delete entries — is one of the hardest problems in distributed systems: stale data and thundering herds (many concurrent misses) are the two failure modes to design against. For the full architecture this cache sits within, see Scalable Web Architecture.