Model Training Pipeline
A model training pipeline is the end-to-end automated workflow that transforms raw labeled data into a trained, evaluated, and registered model artifact ready for deployment.
A model training pipeline is the end-to-end automated workflow that transforms raw labeled data into a trained, evaluated, and registered model artifact ready for deployment.
What the diagram shows
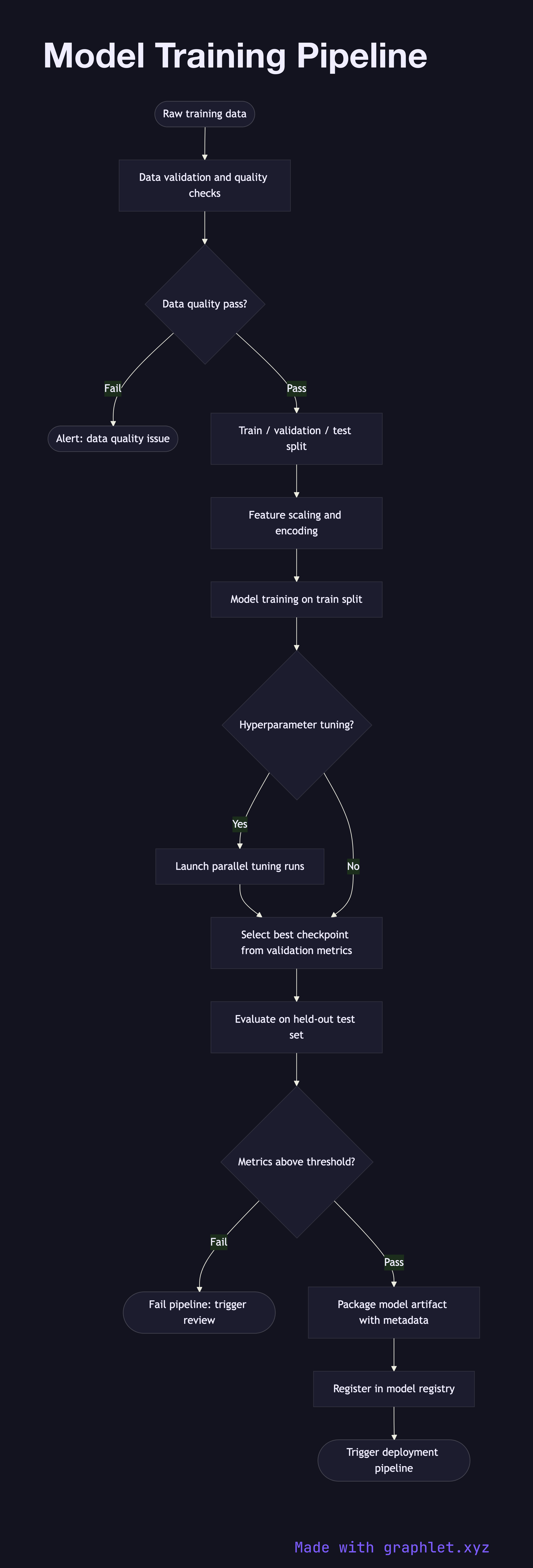
This flowchart walks through each stage of a production ML training pipeline:
1. Raw data ingestion: training data is pulled from data lakes, databases, or feature stores. For structured ML, a Feature Engineering Pipeline runs first to produce clean feature tables. 2. Data validation: schema checks, null value audits, and distribution drift detection are run to catch data quality issues before they corrupt a training run. 3. Train / validation / test split: the dataset is partitioned — typically 70/15/15 — with stratification to preserve label balance. 4. Feature scaling and encoding: numerical features are normalized or standardized; categorical features are one-hot encoded or embedded. 5. Model training: the model is trained on the training split, with the validation split used for early stopping and hyperparameter feedback. 6. Hyperparameter tuning: a search strategy (grid, random, or Bayesian) explores the hyperparameter space, launching multiple training runs in parallel. 7. Evaluation on test set: the best model checkpoint is evaluated against the held-out test set. Key metrics (accuracy, AUC, F1, RMSE) are recorded. 8. Threshold check: if evaluation metrics fall below minimum acceptance thresholds, the pipeline fails and triggers a review. 9. Model registration: the validated model artifact, including weights, preprocessor, and metadata, is versioned and registered in a model registry. 10. Deployment trigger: a passing registration event signals the Model Version Deployment pipeline to promote the new version to staging or production.
Why this matters
Automating the training pipeline ensures reproducibility, enforces quality gates before any model reaches production, and enables rapid iteration through continuous training triggered by the AI Feedback Loop.