Feature Engineering Pipeline
A feature engineering pipeline transforms raw, heterogeneous data sources into clean, normalized, model-ready feature vectors and stores them in a feature store for consistent use during both training and inference.
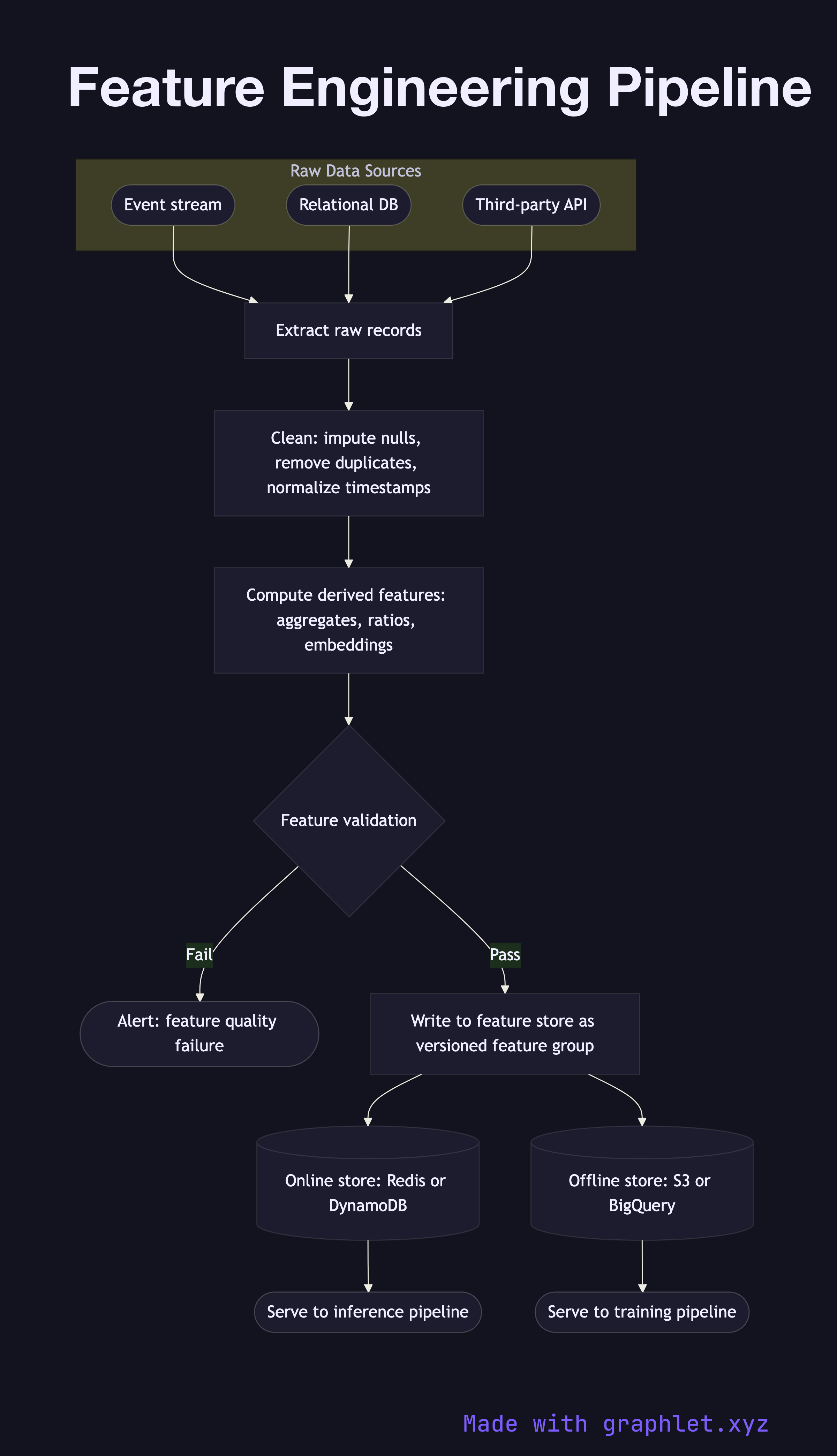
A feature engineering pipeline transforms raw, heterogeneous data sources into clean, normalized, model-ready feature vectors and stores them in a feature store for consistent use during both training and inference.
What the diagram shows
This flowchart traces the data transformation stages from raw sources to a served feature vector:
1. Raw data sources: the pipeline ingests from multiple origins — event streams (clickstreams, transactions), relational databases, third-party APIs, and unstructured logs. 2. Data extraction: connectors pull batches or streams of raw records for the target entities (users, items, sessions). 3. Data cleaning: null values are imputed, outliers are clipped or flagged, duplicate records are removed, and timestamps are normalized to UTC. 4. Feature transformation: domain-specific features are computed — rolling aggregates (7-day purchase count), ratio features (clicks / impressions), lag features, text embeddings, or geospatial encodings. 5. Feature validation: the computed features are checked against predefined expectations: value ranges, distribution bounds, and null rate thresholds. Failures here block writes to the feature store. 6. Feature store write: validated features are written to the feature store under a versioned feature group, indexed by entity key and timestamp. 7. Online store sync: low-latency online store (Redis, DynamoDB) is updated for real-time serving during inference (see Inference Pipeline). 8. Offline store: the full historical feature table is written to the offline store (S3, BigQuery) for training data retrieval (see Model Training Pipeline).
Why this matters
Consistent feature computation between training and serving — the "training-serving skew" problem — is one of the most common sources of ML performance degradation in production. A shared feature store eliminates this class of bug entirely.