AI Feedback Loop
An AI feedback loop is the continuous cycle through which a deployed model collects real-world signals, monitors its own performance, detects degradation, and triggers retraining to maintain or improve accuracy over time.
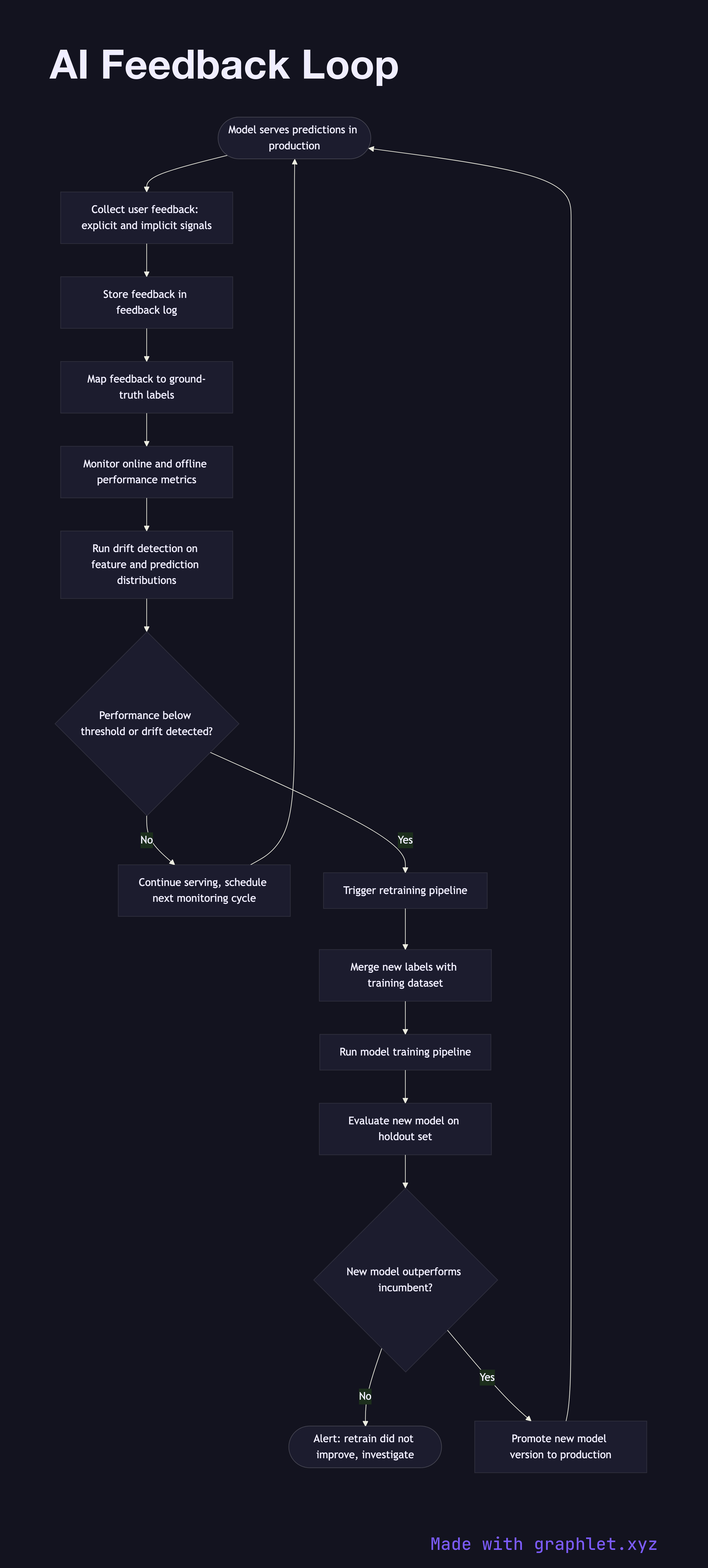
An AI feedback loop is the continuous cycle through which a deployed model collects real-world signals, monitors its own performance, detects degradation, and triggers retraining to maintain or improve accuracy over time.
What the diagram shows
This flowchart maps the closed-loop lifecycle that keeps a production ML system healthy:
1. Model serves predictions: the deployed model generates predictions in response to live requests (see Inference Pipeline). 2. Collect user feedback: explicit feedback (thumbs up/down, ratings, corrections) and implicit signals (clicks, purchases, dwell time) are captured and stored in a feedback log. 3. Label collection: for supervised learning, feedback signals are mapped to ground-truth labels. Implicit signals may go through a labeling pipeline or human review. 4. Monitor model performance: online metrics (click-through rate, conversion rate, rejection rate) and offline metrics are continuously tracked and compared against baseline. 5. Drift detection: statistical tests (PSI, KL divergence, population stability index) flag significant shifts in input feature distributions or prediction distributions. 6. Threshold check: if performance metrics fall below a defined threshold or drift is detected, a retraining trigger is fired. 7. Retrain trigger: the feedback labels are merged with the existing training dataset and a new training run is kicked off (see Model Training Pipeline). 8. Evaluate and promote: the newly trained model is evaluated against holdout data. If it outperforms the incumbent, it is promoted to production (see Model Version Deployment). 9. Loop continues: the promoted model serves new predictions, and the cycle repeats.
Why this matters
Without a feedback loop, model performance silently degrades as the real world drifts away from the training distribution. Automating this cycle is the foundation of MLOps and continuous learning systems.