Inference Pipeline
An inference pipeline is the real-time serving path that transforms a prediction request into a model output — retrieving features, loading the correct model version, running the forward pass, and returning a structured prediction with low latency.
An inference pipeline is the real-time serving path that transforms a prediction request into a model output — retrieving features, loading the correct model version, running the forward pass, and returning a structured prediction with low latency.
What the diagram shows
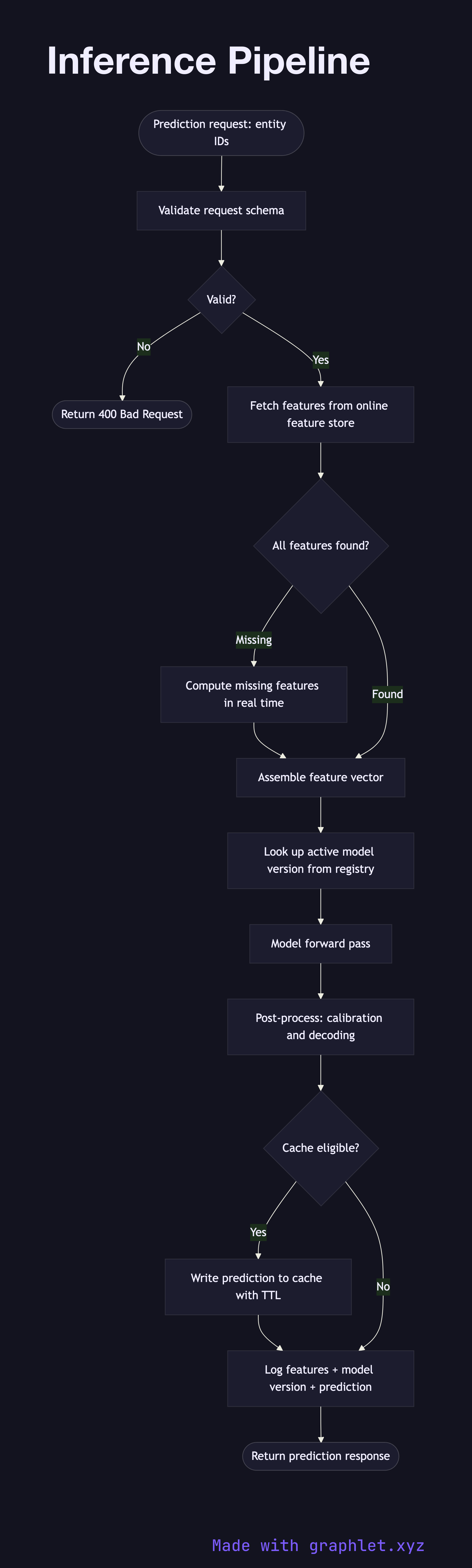
This flowchart maps the execution path of a single inference request through a production ML serving system:
1. Prediction request: an upstream service or user-facing application sends a prediction request containing entity identifiers (e.g., user ID, item ID). 2. Input validation: request schema is validated and required fields are checked before any computation begins. 3. Feature retrieval: the pipeline fetches precomputed features from the online feature store (see Feature Engineering Pipeline). Features absent from the store may fall back to real-time computation. 4. Feature assembly: retrieved features are joined, ordered, and shaped into the exact input tensor format expected by the model. 5. Model version lookup: the serving layer consults the model registry to resolve the currently active model version and its serving endpoint (see Model Version Deployment). 6. Model forward pass: the assembled feature vector is passed to the model, which performs inference and returns raw scores or logits. 7. Post-processing: raw outputs are transformed — scores are calibrated, logits converted to probabilities via softmax, or class labels decoded. 8. Result caching: predictions for high-traffic entity pairs may be cached with a short TTL to reduce repeated model invocations. 9. Logging: input features, model version, and prediction output are logged to a feature/prediction store for downstream use in the AI Feedback Loop.
Why this matters
Low-latency inference with consistent feature retrieval is critical for user-facing ML applications such as recommendation, ranking, and fraud detection. A well-structured inference pipeline separates feature serving from model serving, making each independently scalable.