Distributed Tracing Flow
Distributed tracing is an observability technique that tracks a single request as it travels across multiple services, assigning it a unique trace ID and recording a span for each service hop so engineers can reconstruct the full call graph, identify latency hotspots, and debug failures in distributed systems.
Distributed tracing is an observability technique that tracks a single request as it travels across multiple services, assigning it a unique trace ID and recording a span for each service hop so engineers can reconstruct the full call graph, identify latency hotspots, and debug failures in distributed systems.
What the diagram shows
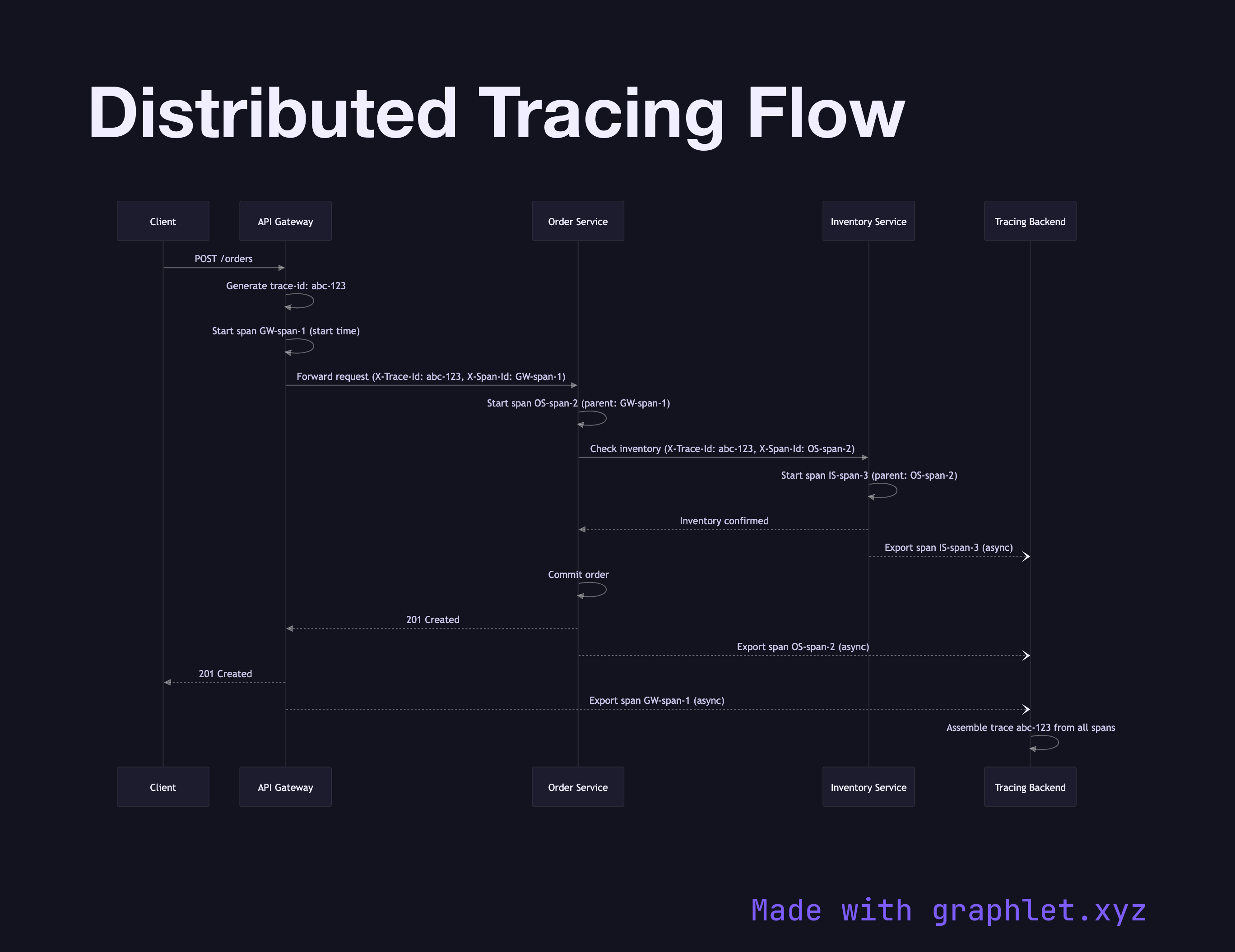
This sequence diagram follows a request from the Client through an API Gateway, Order Service, Inventory Service, and finally to a Tracing Backend (e.g., Jaeger, Zipkin, or OpenTelemetry Collector).
Key mechanics illustrated:
1. Trace ID created at entry: the API Gateway generates a trace-id (e.g., abc-123) and attaches it to the request as a header (X-Trace-Id). 2. Span created per hop: each service creates a child span with its own span-id, recording a start timestamp, end timestamp, and metadata (service name, operation, status). 3. Context propagated downstream: when a service makes a downstream call, it forwards the trace-id and its own span-id (as the parent span ID) in outbound request headers. 4. Spans exported asynchronously: each service reports its span to the tracing backend asynchronously — out of band from the request path — so tracing overhead doesn't add synchronous latency. 5. Trace assembled: the tracing backend assembles all spans for a given trace-id into a waterfall view, showing which service took how long at each step.
Why this matters
In a microservices system, a single user-facing request may touch dozens of services. When latency spikes, logs from individual services don't tell you which hop is slow. Distributed traces give you the full picture in one view. OpenTelemetry has become the vendor-neutral standard for instrumentation, with exporters for Jaeger, Zipkin, Datadog, and others.
Tracing complements the Microservice Request Chain diagram by adding observability on top of the call graph. For async workloads, see Background Job Processing — trace context can be serialized into job queues to trace across async boundaries.