Cloud Backup Strategy
A cloud backup strategy defines how data is copied, retained, and restored to meet Recovery Point Objectives (RPO) and Recovery Time Objectives (RTO) — the core SLAs that quantify how much data loss and downtime a business can tolerate.
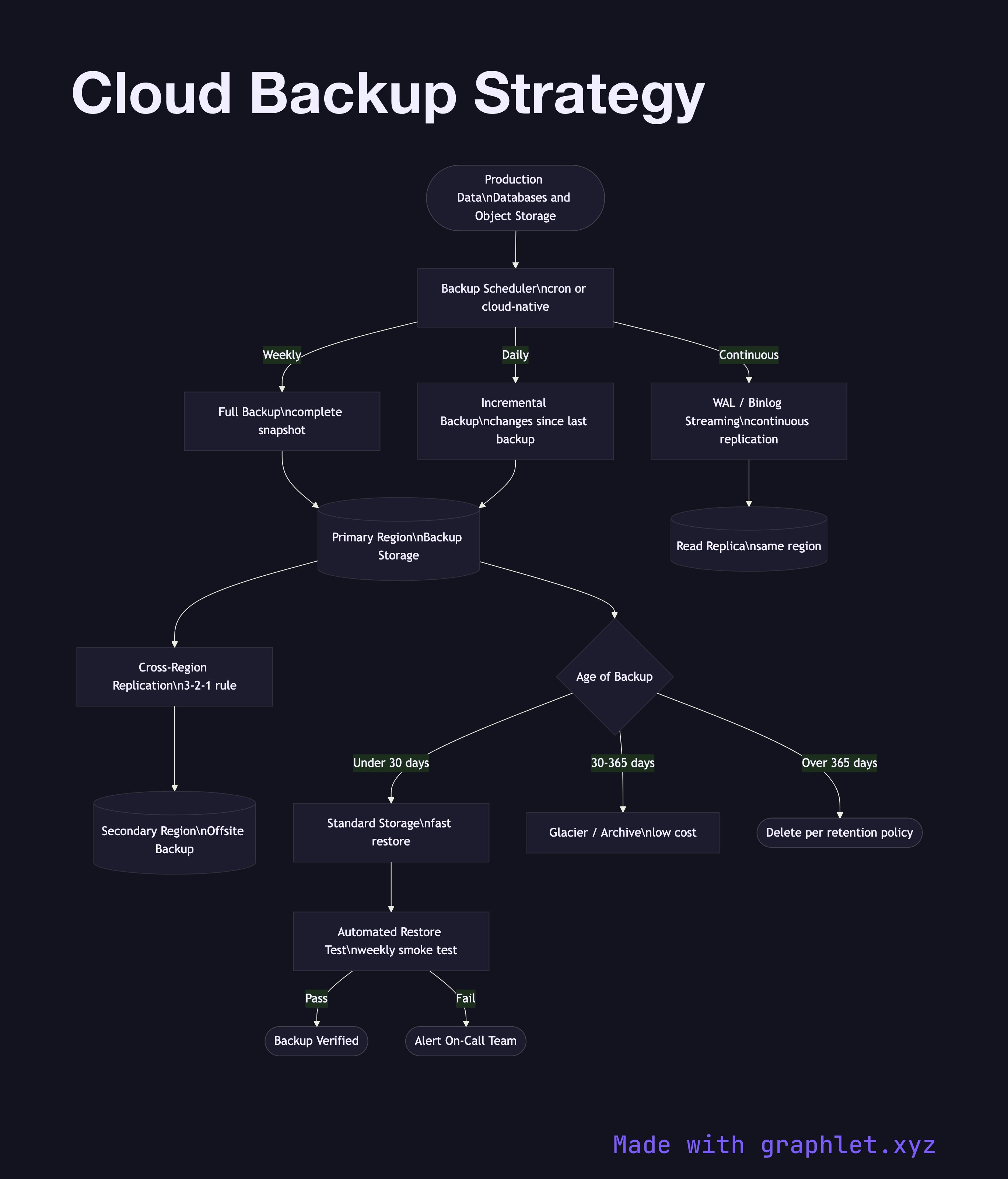
A cloud backup strategy defines how data is copied, retained, and restored to meet Recovery Point Objectives (RPO) and Recovery Time Objectives (RTO) — the core SLAs that quantify how much data loss and downtime a business can tolerate.
RPO is the maximum acceptable age of data that must be recovered after a failure. An RPO of 1 hour means backups must run at least hourly; 15 minutes may require continuous replication. RTO is the maximum acceptable time to restore a service after an outage. Low RTO demands fast restoration paths — warm standby databases, pre-provisioned infrastructure, and tested runbooks.
Cloud backup architectures commonly combine multiple backup types:
- Full backups: A complete snapshot of all data. Simplest to restore but most storage-intensive. Typically run weekly. - Incremental backups: Only changes since the last backup. Fast and storage-efficient. Must chain back to the last full backup for restore. - Differential backups: All changes since the last full backup. Restore requires only the full + one differential. A middle ground. - Continuous replication: Write-ahead logs streamed to a replica in near real-time (AWS RDS read replicas, CloudSQL). Minimal RPO but highest cost.
A 3-2-1 rule is standard: 3 copies of data, on 2 different media, with 1 off-site (cross-region). Lifecycle policies move older backups to cheaper tiers — Glacier after 30 days — controlled by Object Storage Lifecycle rules.
Backups are worthless without verified restores. Automated restore testing — periodically spinning up a restored environment and running smoke tests — is a key operational practice. See Cloud Monitoring Pipeline for monitoring backup job success metrics.