Observability Pipeline
An observability pipeline is the infrastructure that collects, processes, and routes the three pillars of observability — metrics, logs, and traces — from running services to the storage backends and visualization tools that engineers use to understand system behavior.
An observability pipeline is the infrastructure that collects, processes, and routes the three pillars of observability — metrics, logs, and traces — from running services to the storage backends and visualization tools that engineers use to understand system behavior.
How the pipeline works
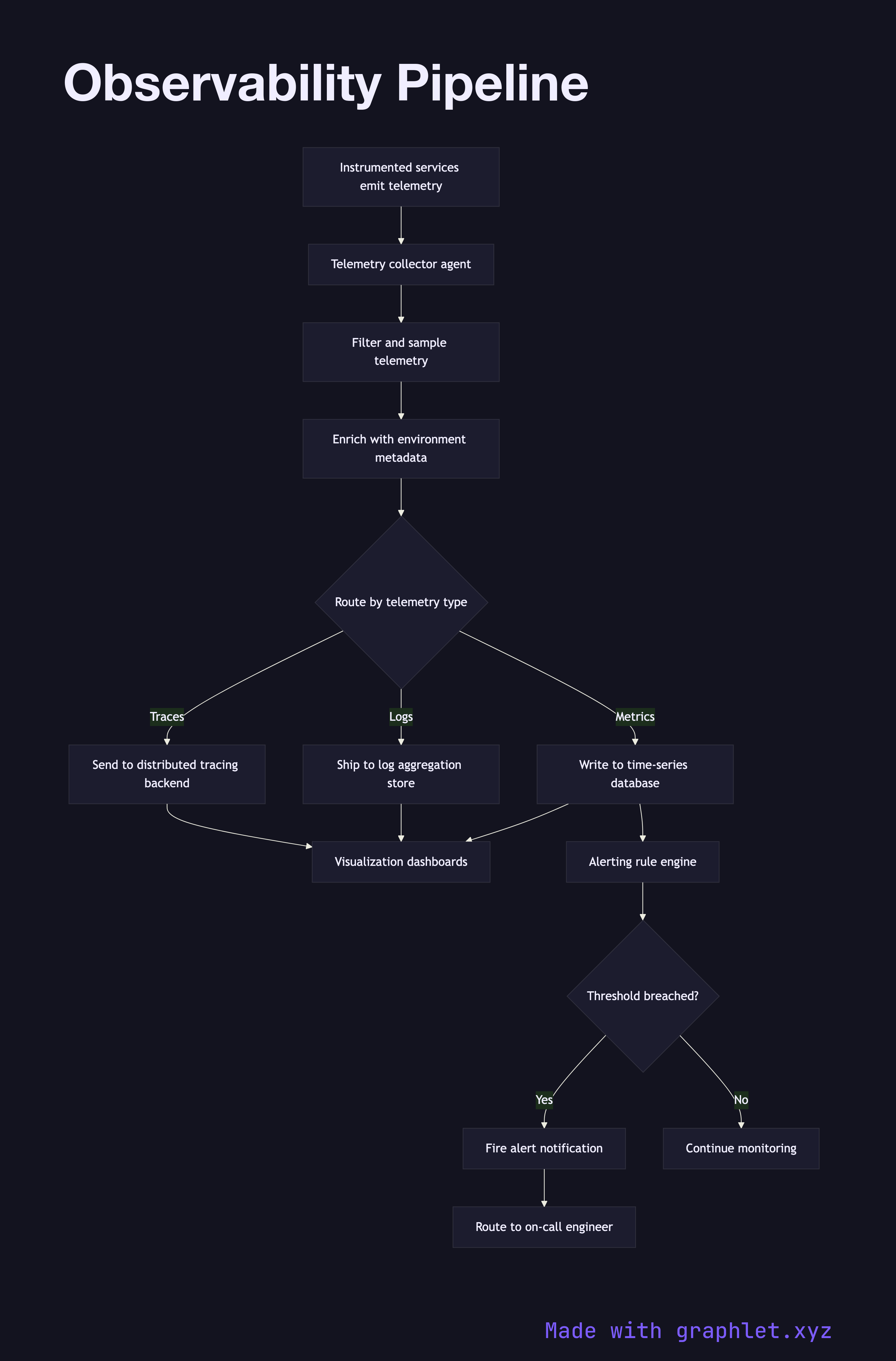
Every running service emits telemetry continuously. Application code is instrumented with an OpenTelemetry SDK or vendor agent that captures three data types:
- Metrics: numeric time-series data (request rates, error counts, CPU usage) emitted at regular intervals - Logs: structured or unstructured text records of discrete events, enriched with trace context - Traces: distributed trace spans that track a request across multiple services and show latency breakdowns
All three streams are collected by a telemetry collector agent running on each host or as a sidecar container. The collector performs initial processing: filtering out high-cardinality noise, sampling traces to a configurable rate, enriching records with environment metadata (service name, version, datacenter), and batching for efficient transmission.
Processed telemetry is then routed to specialized backends. Metrics are written to a time-series database like Prometheus or InfluxDB. Logs are shipped to an aggregation store like Elasticsearch or Loki (see Log Aggregation Pipeline). Traces are sent to a distributed tracing backend like Jaeger or Tempo.
A visualization layer (Grafana, Datadog, etc.) queries all three backends, allowing engineers to correlate a spike in the error rate metric with the specific log lines and the distributed trace that caused it. The alerting system subscribes to the metrics backend and fires notifications when thresholds are breached (see Alerting Workflow).