Distributed Task Scheduling
Distributed task scheduling is the process by which a cluster manager assigns units of work (tasks, jobs, or containers) to worker nodes, managing resource constraints, priorities, failure recovery, and load balancing across a pool of heterogeneous machines.
Distributed task scheduling is the process by which a cluster manager assigns units of work (tasks, jobs, or containers) to worker nodes, managing resource constraints, priorities, failure recovery, and load balancing across a pool of heterogeneous machines.
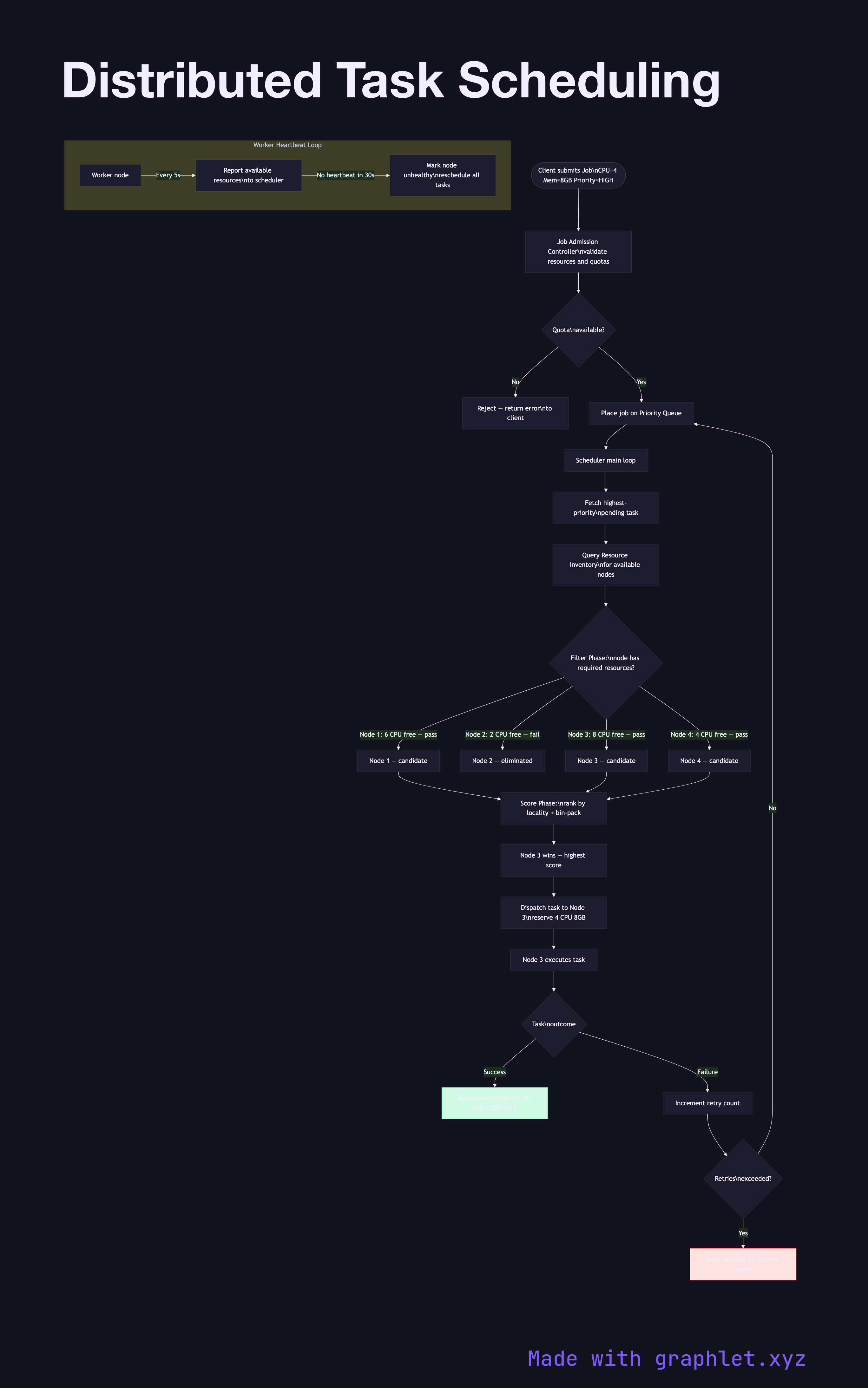
Modern distributed schedulers operate in a continuous control loop: accept job submissions, match tasks to available resources, dispatch work, monitor execution, and reschedule failed tasks — all without a single point of failure.
Job Submission and Queueing: Clients submit jobs with resource requirements (CPU, memory, GPU), priority, and dependency constraints. A job admission controller validates the request and places it on a priority queue. Dependency-aware schedulers (like Apache Airflow's DAG executor) will not schedule a task until all its upstream dependencies have successfully completed.
Resource Tracking: Worker nodes periodically report their available resources (heartbeat) to the scheduler. The scheduler maintains a resource inventory, tracking both total and currently allocated capacity. Kubernetes uses an informer-based watch mechanism rather than polling to keep this state consistent.
Task Placement: The scheduler selects candidate nodes by filtering (does the node have sufficient resources?) and then scoring (which candidate is optimal for locality, bin-packing, or spreading?). Algorithms range from simple round-robin and least-loaded to bin-packing (Tetris, Google Borg) and fair-share (YARN's DRF).
Failure Handling: If a worker node stops sending heartbeats, all tasks on that node are re-queued and rescheduled. Idempotent tasks can be speculatively executed on a second node in parallel (Hadoop's speculative execution) to reduce tail latency. See MapReduce Execution for how batch task graphs execute under this scheduler, and Cluster Coordination Architecture for how the scheduler itself achieves high availability.