MapReduce Execution
MapReduce is a parallel data processing model in which large datasets are processed in two functional phases — Map and Reduce — automatically distributed across a cluster, with the framework handling task assignment, failure recovery, and data shuffling between phases.
MapReduce is a parallel data processing model in which large datasets are processed in two functional phases — Map and Reduce — automatically distributed across a cluster, with the framework handling task assignment, failure recovery, and data shuffling between phases.
Introduced by Google in 2004 and popularized by Apache Hadoop, MapReduce hides the complexity of distributed execution behind a simple programming model: the developer writes two pure functions, and the framework does the rest.
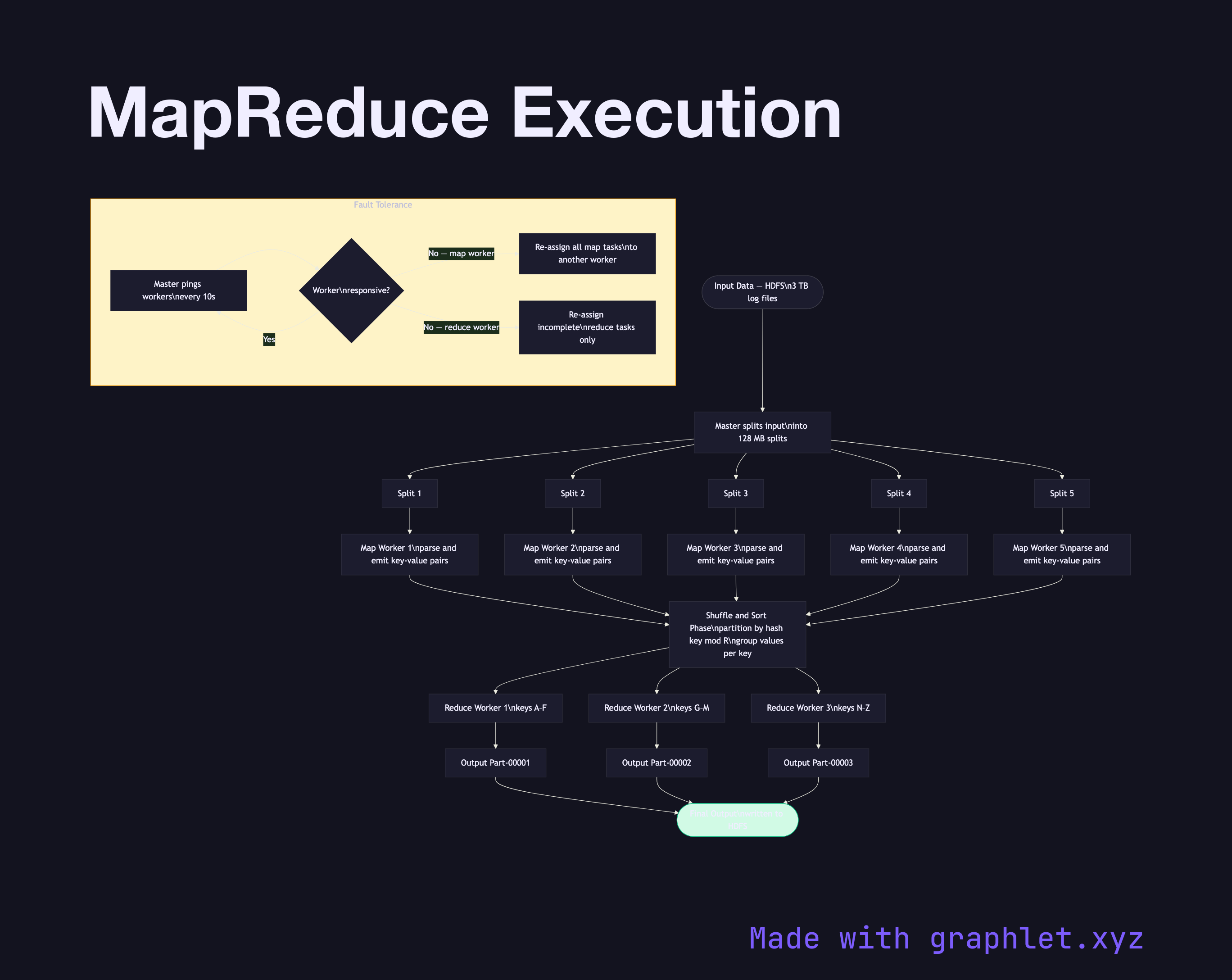
Input Splitting: The framework divides input data (typically files in HDFS or GCS) into fixed-size input splits (default 128 MB in Hadoop). Each split is processed by one Map task, and splits are placed on nodes that hold a local replica of that data — minimizing network I/O through data locality.
Map Phase: Each Map worker reads its assigned input split, parses records, and calls the user-provided map(key, value) → list(intermediate_key, intermediate_value) function. Output key-value pairs are buffered in memory, sorted by key, and spilled to local disk partitioned by reducer ID (determined by hash(intermediate_key) % R, where R is the number of reducers).
Shuffle and Sort: Reduce workers pull their assigned partitions from all Map workers over the network. This network-intensive phase is called the shuffle. The framework merges and sorts all pulled partitions by key, grouping all values for the same key together.
Reduce Phase: Each Reduce worker calls reduce(key, list(values)) → list(output_value) for each unique key group. Output is written to the distributed filesystem. With R reducers, the job produces R output files.
Fault Tolerance: The master periodically pings worker nodes. If a Map worker fails, all its completed tasks are re-executed (because intermediate output is on local disk). If a Reduce worker fails, only incomplete tasks are restarted. See Distributed Task Scheduling for how the master assigns tasks, and Data Replication Strategy for how HDFS stores the input data reliably.