IoT Data Aggregation
IoT data aggregation is the process of combining high-frequency raw sensor readings into progressively coarser time-series rollups — minute averages, hourly summaries, daily statistics — enabling efficient long-term storage, fast query performance, and meaningful trend analysis without retaining every individual sample indefinitely.
IoT data aggregation is the process of combining high-frequency raw sensor readings into progressively coarser time-series rollups — minute averages, hourly summaries, daily statistics — enabling efficient long-term storage, fast query performance, and meaningful trend analysis without retaining every individual sample indefinitely.
Raw IoT telemetry is expensive to store and slow to query at scale. A sensor reporting at 1 Hz generates 86,400 readings per day per device. A fleet of 10,000 devices produces 864 million raw records daily. Querying "average temperature last month by building" across this volume would be prohibitively slow without pre-aggregated rollup tables.
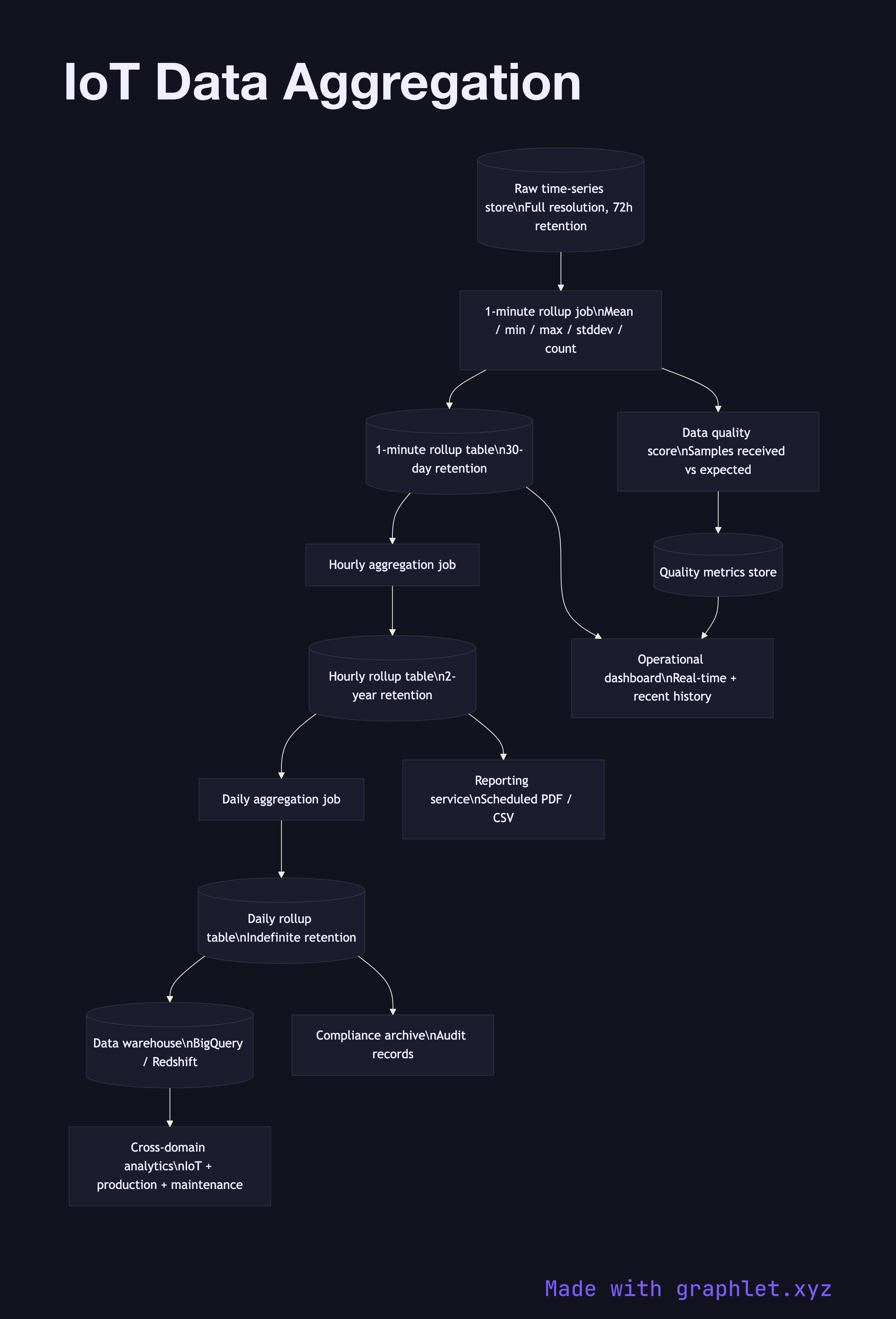
The aggregation pipeline begins with the raw time-series store, which holds full-resolution data for a short retention window (typically 24–72 hours). A 1-minute rollup job runs continuously, reading each device's raw samples in the most recent complete minute window and computing: mean, min, max, standard deviation, and sample count. These rollup records are written to a 1-minute rollup table with a longer retention (30–90 days).
Downstream, an hourly aggregation job reads from the 1-minute rollups (not the raw table) and computes hourly statistics with even longer retention (1–2 years). A daily aggregation job does the same from hourly rollups and is retained indefinitely for compliance and long-term trend analysis. Each rollup tier also computes a data quality score — the ratio of expected samples to received samples — flagging gaps caused by device downtime or connectivity issues.
The aggregated data serves multiple consumers: operational dashboards displaying real-time and recent-history charts, reporting services generating scheduled PDF or CSV reports, and a data warehouse that combines IoT metrics with business data (production records, maintenance logs) for cross-domain analysis. For the upstream ingestion feeding this pipeline, see IoT Telemetry Pipeline. For the broader device-to-cloud flow, see IoT Device Data Flow. For the sensor-level pipeline that produces the raw data, see IoT Sensor Data Pipeline.