Search Relevance Feedback
Search relevance feedback is the closed-loop process that captures signals from user behavior and explicit judgments, feeds them back into ranking models, and continuously improves the quality of search results over time.
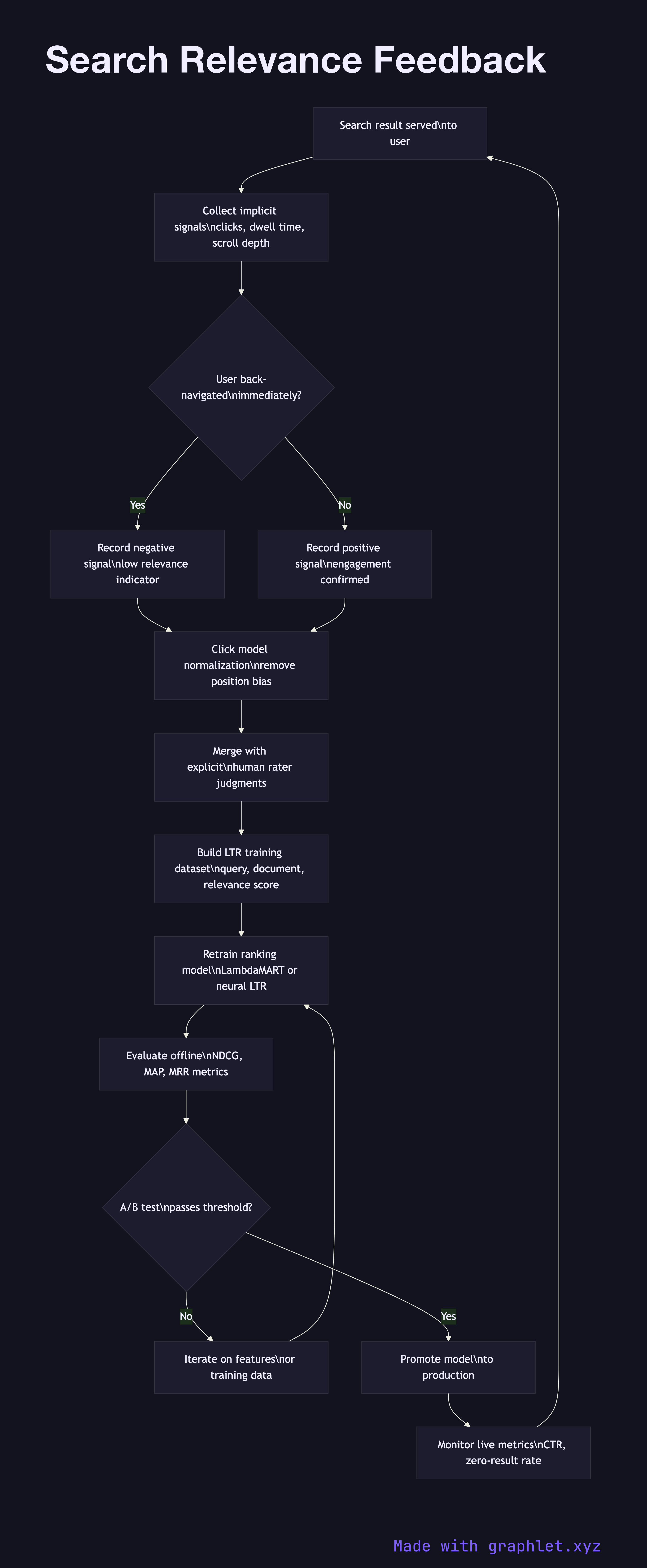
Search relevance feedback is the closed-loop process that captures signals from user behavior and explicit judgments, feeds them back into ranking models, and continuously improves the quality of search results over time.
How relevance feedback works
Implicit signal collection captures behavioral events that proxy for relevance without requiring explicit user input: clicks on results, time spent on the clicked page (dwell time), scroll depth, back-navigation (a strong negative signal — the user returned immediately), and add-to-cart or conversion events in e-commerce search.
Explicit judgment collection gathers deliberate relevance labels from human raters or from users who rate results. Rater programs use a relevance scale (Perfect, Excellent, Good, Fair, Bad) applied to query-document pairs. These labels are expensive to produce but highly reliable, and they serve as the training signal for learning-to-rank models.
Click model normalization corrects for position bias — users click higher-ranked results more often regardless of their relevance, because they trust the ranker or simply because they see top results first. Models like UBM (User Browsing Model) or DBN (Dynamic Bayesian Network) de-bias raw click data to estimate true relevance.
Training data pipeline aggregates normalized implicit signals and explicit judgments into a dataset of (query, document, relevance_score) triples. This dataset is versioned, split into train and validation sets, and used to retrain the Ranking Algorithm Pipeline LTR model on a regular cadence.
Model evaluation and A/B testing measures the new model's performance on held-out validation data (NDCG, MAP, MRR) and then in a live experiment against the incumbent model, tracking click-through rate, session success rate, and zero-result rate.
Model promotion replaces the production ranker with the new model after it passes evaluation thresholds. Metrics are tracked by the Search Analytics Pipeline, and the cycle repeats.