Search Query Processing
Search query processing is the real-time path that takes a user's raw input string and produces a ranked list of relevant results, typically within 100 milliseconds.
Search query processing is the real-time path that takes a user's raw input string and produces a ranked list of relevant results, typically within 100 milliseconds.
How query processing works
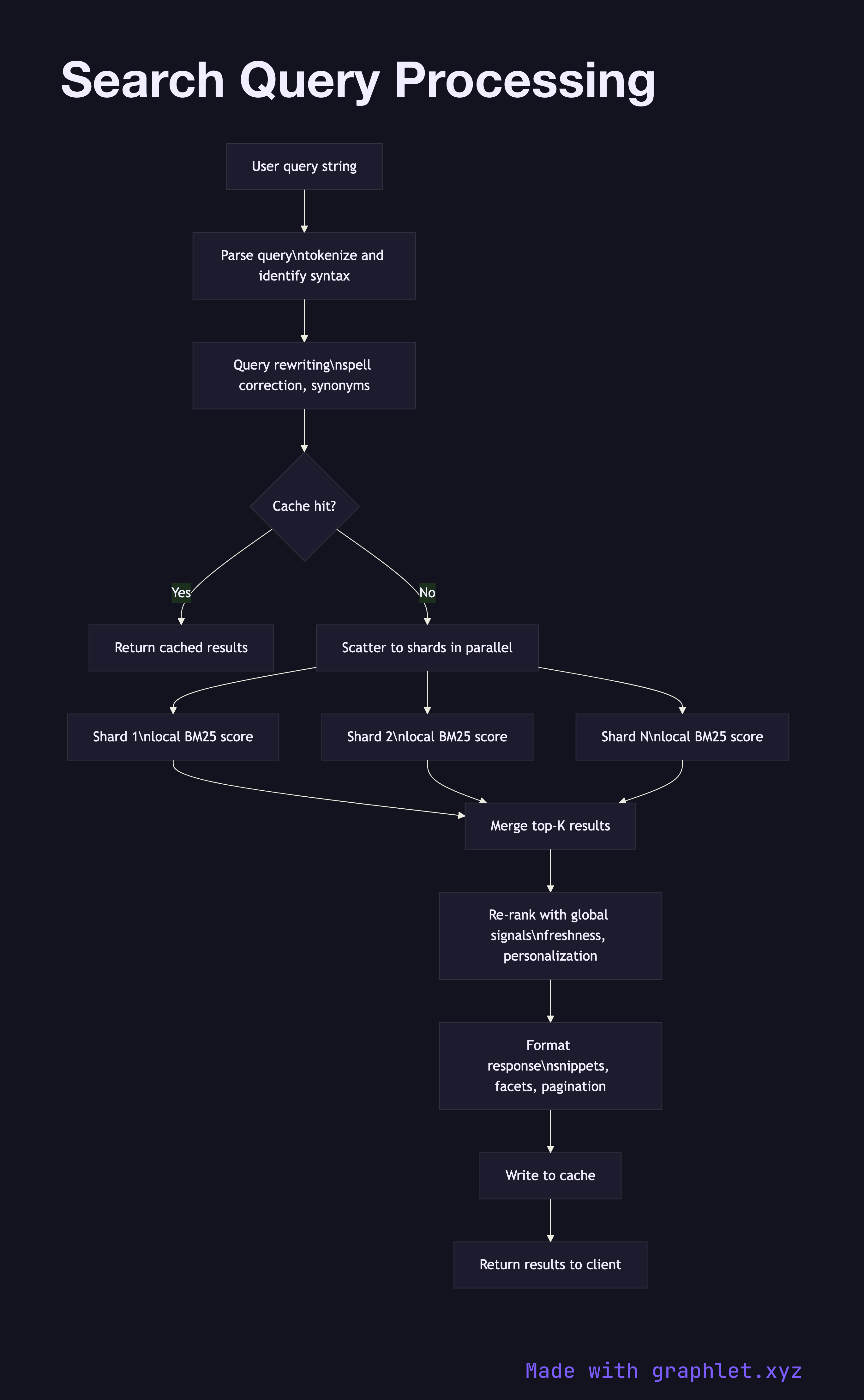
Query parsing is the first transformation. The raw string is tokenized using the same pipeline applied at index time, ensuring that the terms the user types match the tokens stored in the inverted index. The parser also identifies any query syntax: quoted phrases, boolean operators (AND, OR, NOT), field-scoped terms like title:kubernetes, and range filters.
Query rewriting improves recall and precision before execution begins. Spell correction replaces obvious misspellings with dictionary-matched alternatives. Synonym expansion adds equivalent terms — a search for "sofa" might be rewritten to match "couch" and "settee" as well. Query relaxation drops low-value terms from over-constrained queries that would otherwise return zero results.
Cache lookup checks whether an identical or semantically equivalent query was recently executed and the results are still fresh. Search result caches dramatically reduce load on the index for popular queries. The Search Result Caching diagram covers this layer in detail.
Scatter-gather execution fans the query out to all relevant shards in parallel. Each shard searches its local segment of the inverted index, scores matching documents using a ranking function such as BM25, and returns its top-K local results with scores. Because each shard sees only its subset of the corpus, the global top-K must be assembled at the coordinator.
Merge and re-rank collects the per-shard top-K lists, merges them, and applies global ranking signals that require visibility across the full result set: personalization, query-specific freshness boosts, diversity penalties, and machine-learned ranking models. The Ranking Algorithm Pipeline explains this phase in depth.
Result formatting serializes the final ranked list into the response format the client expects — JSON fields, snippets with highlighted matching terms, facet counts, spelling suggestions, and pagination cursors. The formatted response is written back to the cache before being returned to the caller.