Ranking Algorithm Pipeline
A ranking algorithm pipeline determines the order in which search results are presented to the user — transforming a set of candidate documents that match the query into a single ordered list that maximizes relevance and user satisfaction.
A ranking algorithm pipeline determines the order in which search results are presented to the user — transforming a set of candidate documents that match the query into a single ordered list that maximizes relevance and user satisfaction.
How the ranking pipeline works
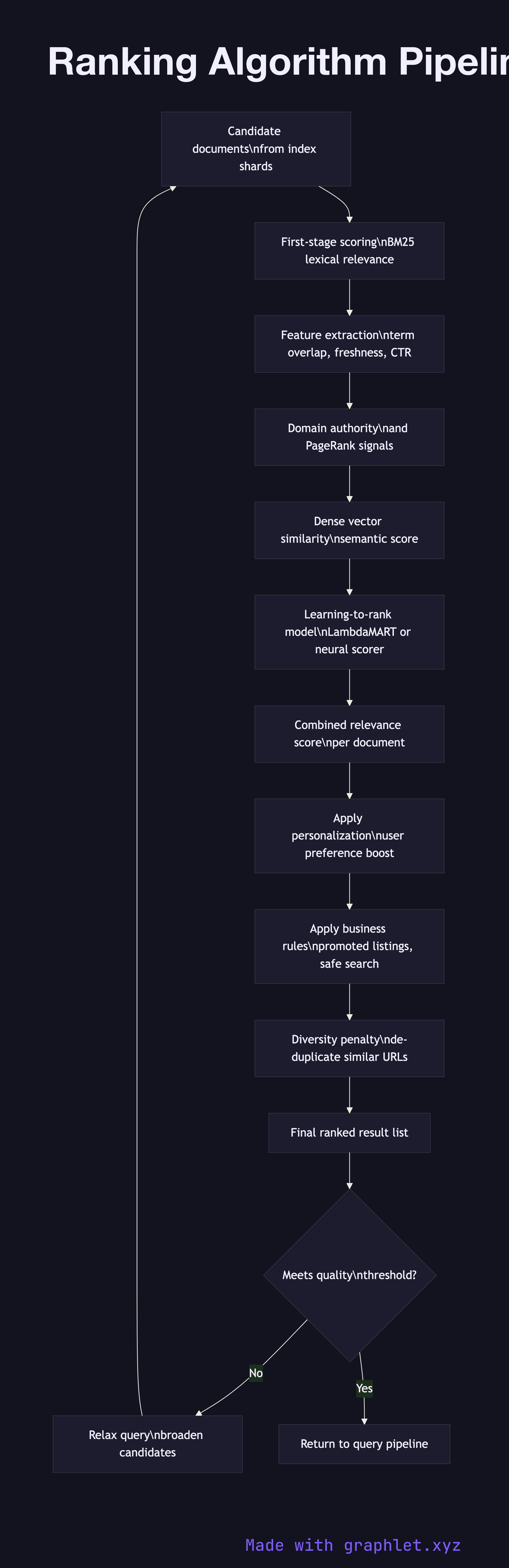
Candidate retrieval produces an initial set of documents that satisfy the query's boolean constraints. This phase optimizes for recall: it would rather return too many candidates than miss a relevant result. In a typical architecture, each shard returns its local top-K documents, and the coordinator merges them into a global candidate pool.
First-stage scoring applies a fast lexical relevance model, most commonly BM25 (Best Match 25). BM25 scores each document based on the term frequency of query tokens in the document, inverse document frequency across the corpus, and a document length normalization factor. The result is a rough relevance signal computed without any expensive feature extraction.
Feature extraction computes a richer set of signals for each candidate: query-document term overlap beyond BM25, PageRank or domain authority, document freshness (recency of last modification), URL and title match strength, click-through rate history for this query-document pair, and optional dense vector similarity from a semantic embedding model.
Learning-to-rank (LTR) model combines the extracted features using a trained model — a gradient-boosted tree (LambdaMART), a neural point-wise scorer, or a cross-encoder — to produce a final relevance score. LTR models are trained offline on human relevance judgments or click logs and updated periodically.
Personalization and diversity applies post-model adjustments: boosting results matching the user's historical preferences, demoting duplicate or near-duplicate URLs, enforcing category diversity so the top 10 results span multiple content types, and applying business rules like promoted listings or safe-search filters.
Final ranked list is returned to the Search Query Processing merge step. Quality is measured through A/B testing on click-through rate, dwell time, and explicit relevance feedback collected by the Search Relevance Feedback loop.