Search Suggestion Engine
A search suggestion engine generates query recommendations that guide users toward better-formed searches — extending autocomplete with semantic intent understanding, related-query suggestions, and behavioral co-click patterns.
A search suggestion engine generates query recommendations that guide users toward better-formed searches — extending autocomplete with semantic intent understanding, related-query suggestions, and behavioral co-click patterns.
How the suggestion engine works
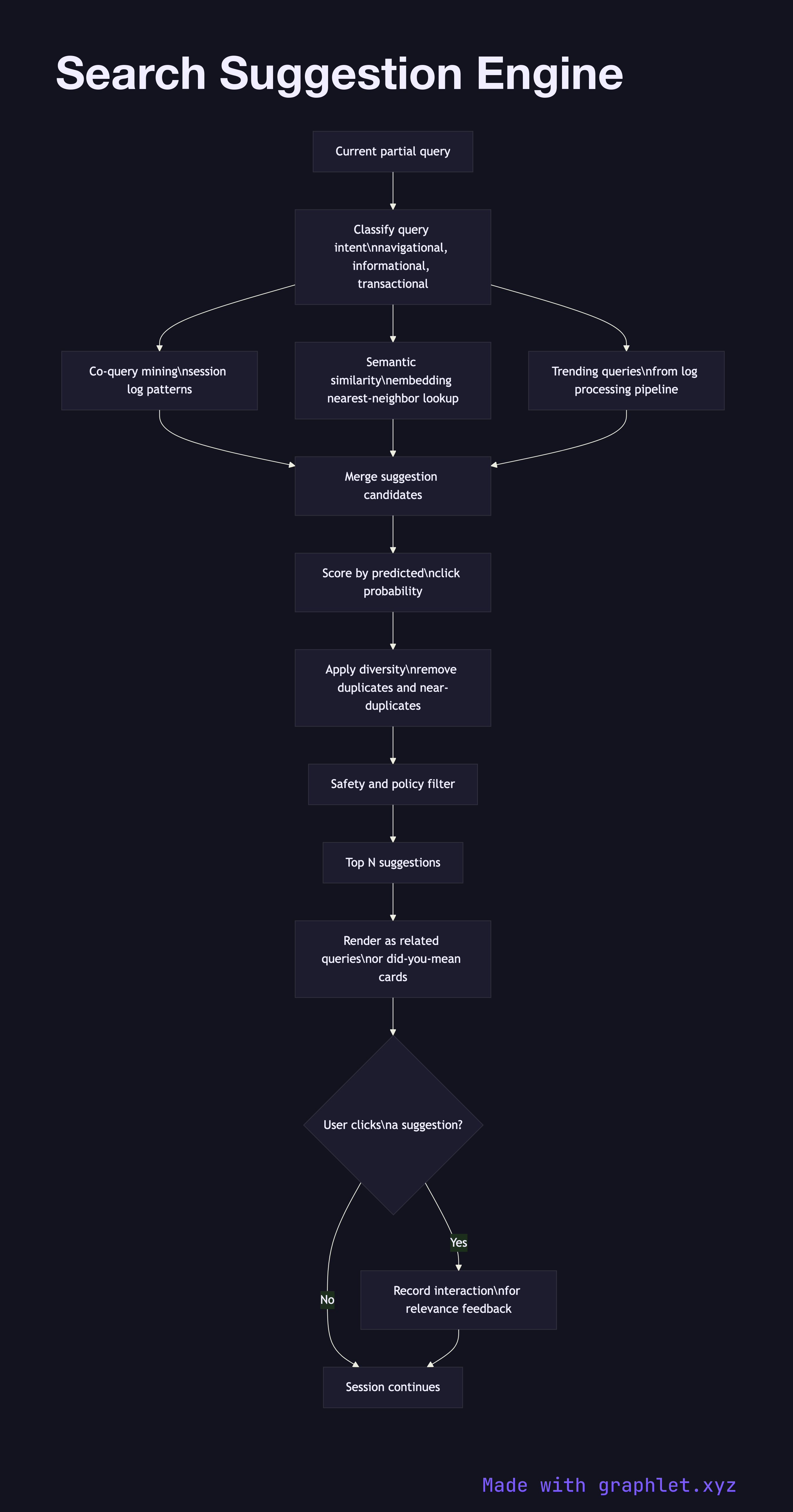
Input classification examines the current query to determine its type: navigational (the user wants a specific site), informational (the user wants to learn something), or transactional (the user wants to do or buy something). Classification shapes which suggestion strategies are applied.
Co-query mining analyzes historical session logs to find queries that users frequently issue in sequence or after reformulating a failed query. If many users who search "how to reverse a string python" next search "python string slicing", those two queries are co-query related and "python string slicing" becomes a candidate suggestion.
Semantic similarity uses dense vector embeddings to surface queries that are semantically related but lexically different. A query for "headache remedies" might yield suggestions like "migraine treatment" and "pain relief without medication" from a nearest-neighbor lookup in embedding space. This draws on the same embedding infrastructure described in Embedding Generation Flow.
Trending and seasonal signals boost suggestions that are currently experiencing elevated search volume, captured by the Search Log Processing pipeline. A trending topic that matches the user's query context will be surfaced prominently.
Candidate ranking merges suggestions from all sources and scores them by predicted click probability, estimated result quality, and diversity. The ranked list is filtered for safety and relevance before being returned.
Suggestion rendering presents the final set as "People also search for" cards, "Did you mean" corrections, or related-query links beneath search results. User interactions with suggestions feed back into the Search Relevance Feedback loop, continuously improving suggestion quality.