Embedding Generation Flow
Embedding generation is the process of converting text, images, or other data into dense numerical vectors that capture semantic meaning, enabling similarity search, clustering, and retrieval-augmented generation.
Embedding generation is the process of converting text, images, or other data into dense numerical vectors that capture semantic meaning, enabling similarity search, clustering, and retrieval-augmented generation.
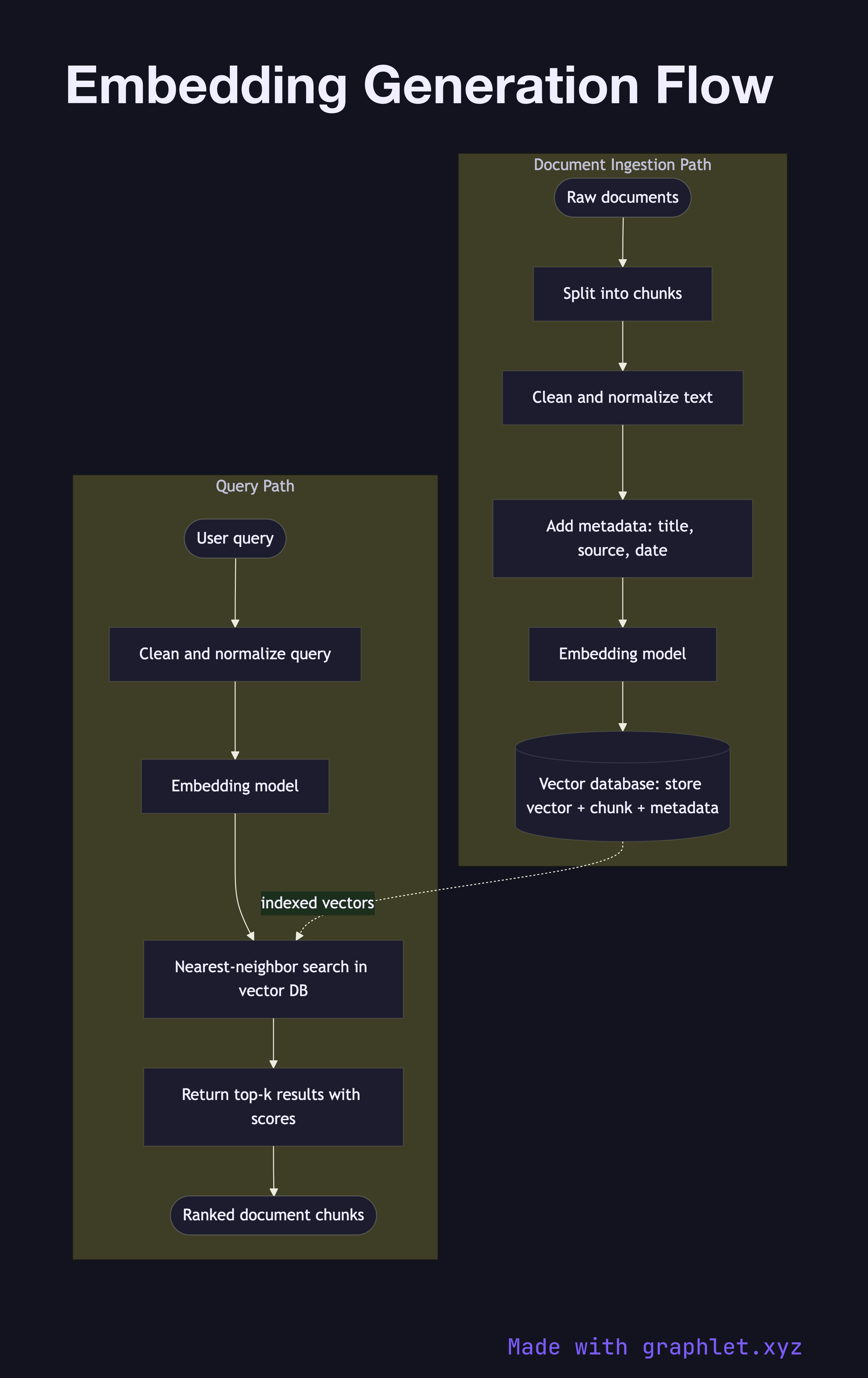
What the diagram shows
This flowchart covers both the document ingestion path (indexing time) and the query path (retrieval time):
Document ingestion: 1. Raw documents: source data such as web pages, PDFs, database records, or knowledge base articles enters the pipeline. 2. Chunking: documents are split into smaller segments — typically 256–1024 tokens — to ensure each chunk fits within the embedding model's context window and represents a coherent semantic unit. 3. Preprocessing: chunks are cleaned (HTML stripped, whitespace normalized) and optionally enriched with metadata such as document title or section heading. 4. Embedding model: the preprocessed text is passed to an embedding model (e.g., text-embedding-ada-002, e5-large, or a fine-tuned bi-encoder). The model outputs a fixed-dimension float vector. 5. Vector storage: the vector is stored in a vector database alongside its source chunk text and metadata (see Vector Database Query).
Query path: 1. Query input: a user query or search string is received. 2. Same preprocessing: the query is cleaned using the same normalization applied to documents. 3. Embedding model: the query is encoded using the same model to ensure vectors are in the same embedding space. 4. Nearest-neighbor search: the query vector is used to search the vector database for the most semantically similar document vectors.
Why this matters
Embeddings are the foundation of modern semantic search and RAG systems. Consistency between the document and query embedding paths — same model, same preprocessing — is essential for retrieval quality. See RAG Architecture for how embedding generation fits into the full pipeline.