AI Ranking Pipeline
An AI ranking pipeline is a multi-stage system that takes a large pool of candidate items and progressively narrows and re-orders them using increasingly powerful (and expensive) models, ultimately producing a personalized ranked list for a specific user and context.
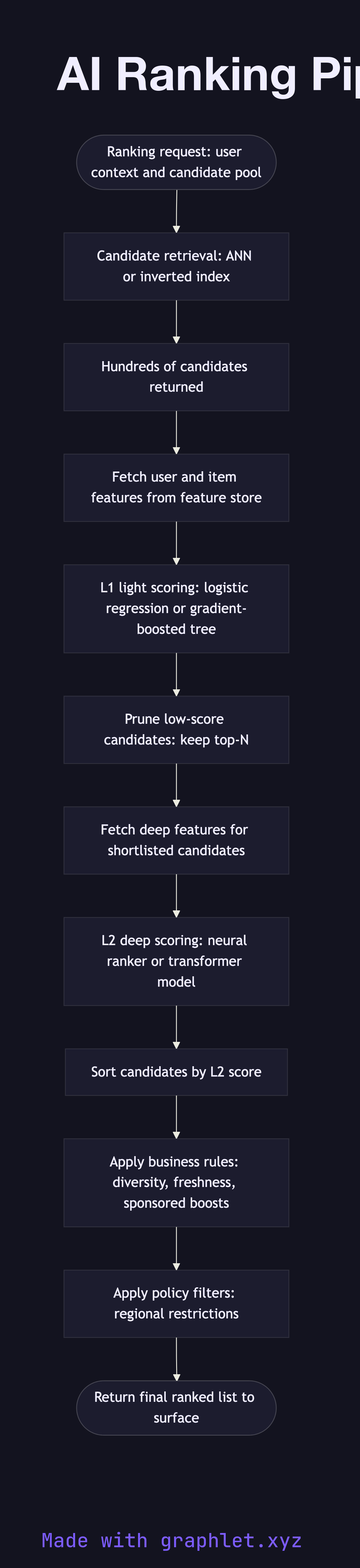
An AI ranking pipeline is a multi-stage system that takes a large pool of candidate items and progressively narrows and re-orders them using increasingly powerful (and expensive) models, ultimately producing a personalized ranked list for a specific user and context.
What the diagram shows
This flowchart illustrates the classic funnel architecture used in production ranking systems for feeds, search results, and recommendation surfaces:
1. Request context: a ranking request arrives with user context (user ID, session data, query or surface) and a pool of candidate items. 2. Candidate retrieval: a fast retrieval layer (ANN lookup, inverted index, or collaborative filtering) narrows the full item corpus from millions to hundreds of candidates. 3. Feature assembly: real-time and precomputed features are fetched for each user-item pair from the feature store (see Feature Engineering Pipeline). Features include user history, item popularity, contextual signals, and freshness. 4. Light scoring (L1): a lightweight model (logistic regression, gradient-boosted tree) scores all candidates quickly. This stage is optimized for low latency over maximum accuracy. 5. Top-N selection: the lowest-scoring candidates are pruned, keeping only the top N for deeper scoring. 6. Deep scoring (L2): a more powerful model (neural network, transformer-based ranker) produces precise relevance scores for the shortlist. This stage can afford higher latency because it operates on fewer items. 7. Business rules overlay: final scores are adjusted for diversity, sponsored items, freshness boosts, or policy constraints (e.g., content restrictions by region). 8. Final ranked list: the adjusted list is returned to the calling surface for display.
Why this matters
A single-stage ranker cannot scale — applying a deep neural network to millions of items per request is computationally infeasible. The multi-stage funnel makes production ranking practical by applying cheap models broadly and expensive models narrowly. See AI Recommendation System for how ranking fits into a full recommendation stack.