AI Moderation Pipeline
An AI moderation pipeline is a multi-stage content safety system that screens both user inputs and model outputs for policy violations — including hate speech, self-harm content, PII, and prompt injection attacks — before content is processed or returned.
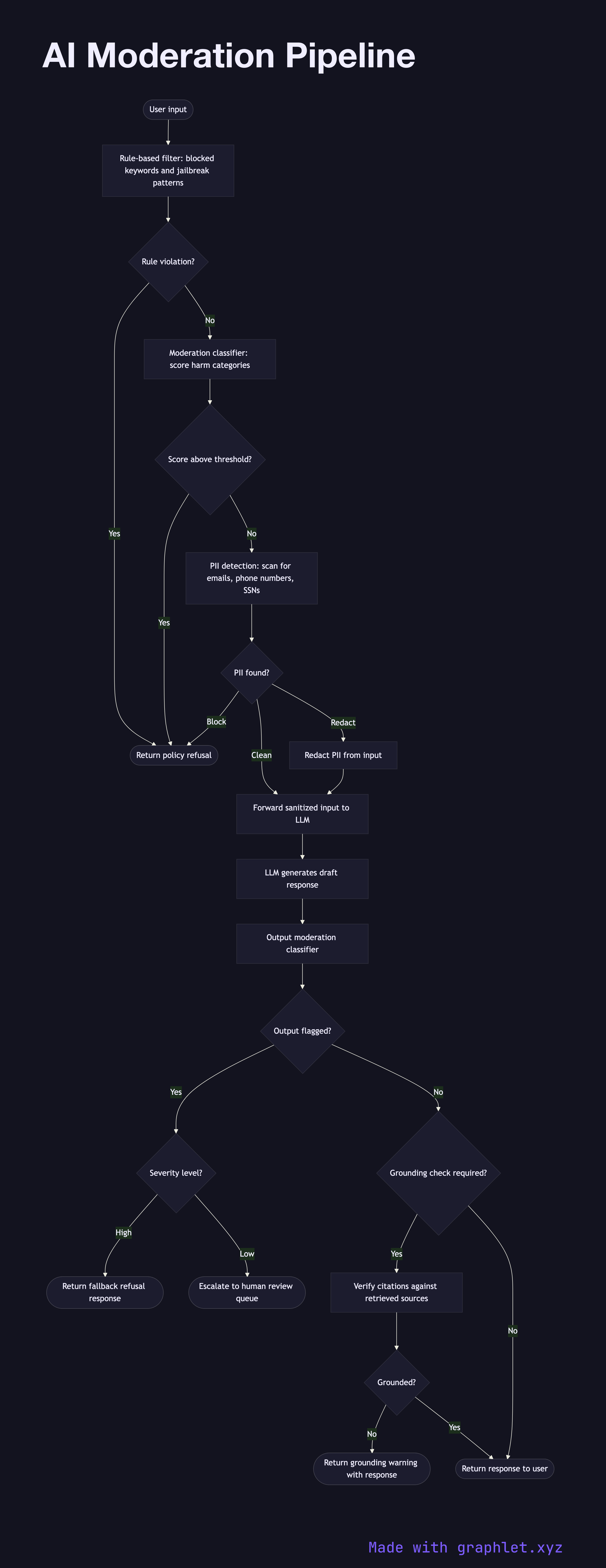
An AI moderation pipeline is a multi-stage content safety system that screens both user inputs and model outputs for policy violations — including hate speech, self-harm content, PII, and prompt injection attacks — before content is processed or returned.
What the diagram shows
This flowchart illustrates a dual-path moderation architecture that runs on both the input and output sides of an LLM inference call:
Input moderation: 1. User input received: raw user text arrives at the application. 2. Rule-based filters: fast, deterministic rules catch obvious violations — blocked keywords, known jailbreak patterns, excessive repetition. 3. Classifier screening: a lightweight moderation classifier (e.g., OpenAI Moderation API, a fine-tuned BERT model) scores the input across harm categories. 4. PII detection: a named entity recognizer scans for personally identifiable information (email addresses, phone numbers, SSNs) and either blocks or redacts it. 5. Block or continue: if any check flags the input, a policy refusal is returned immediately. Otherwise the sanitized input proceeds to the LLM.
Output moderation: 1. LLM generates response: the model produces a draft response. 2. Output classifier: the generated text is screened by the same or a separate moderation classifier. 3. Factual grounding check (optional): for RAG systems, citations are verified against retrieved sources to reduce hallucination risk. 4. Policy decision: clean output is returned to the user; flagged output triggers a fallback response or escalation to human review.
Why this matters
Running moderation on both input and output creates defense in depth. Input moderation blocks attempts to manipulate the model; output moderation catches cases where the model produces unsafe content despite a benign-looking input. See AI Content Generation Pipeline for the broader generation context.