Prompt Processing Pipeline
A prompt processing pipeline is the set of transformation steps that convert raw user input into the structured, context-enriched message array that is actually sent to a language model.
A prompt processing pipeline is the set of transformation steps that convert raw user input into the structured, context-enriched message array that is actually sent to a language model.
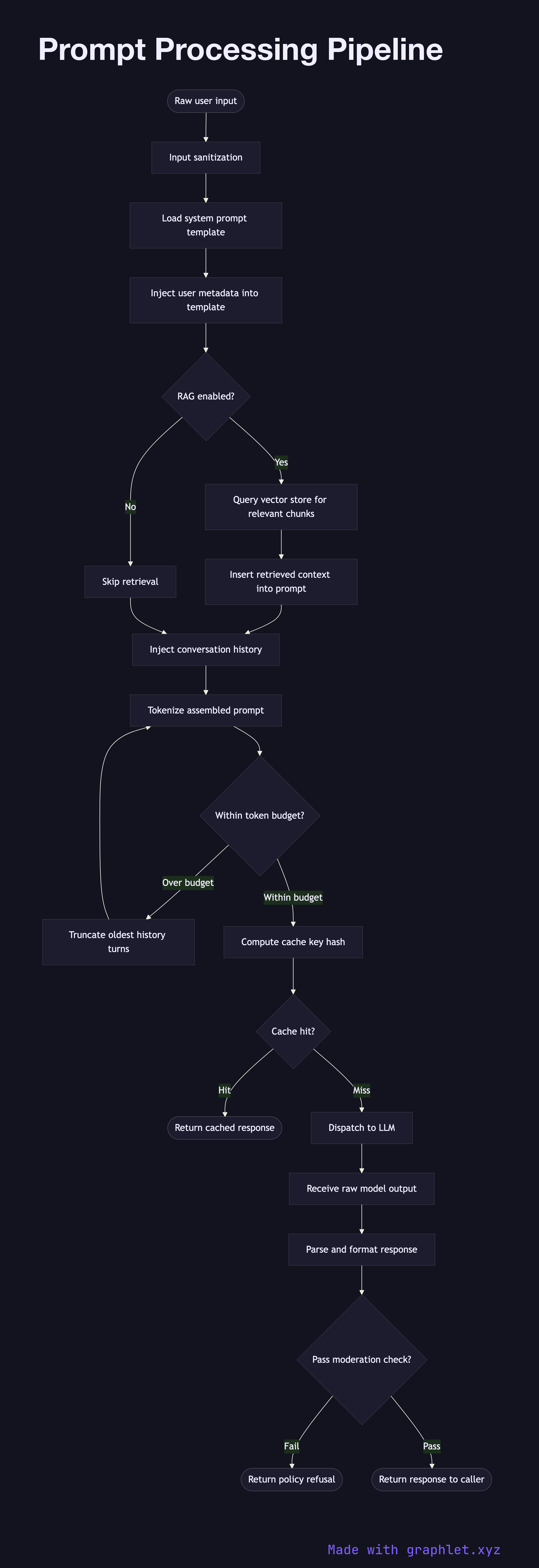
What the diagram shows
This flowchart illustrates each stage a message passes through before reaching the model:
1. Raw user input: the pipeline begins with the unprocessed text submitted by a user or an upstream system. 2. Input sanitization: special characters, injection patterns, and encoding anomalies are cleaned to prevent prompt injection attacks. 3. System prompt assembly: a base system prompt is loaded from a template store, parameterized with user metadata such as role, locale, or product context. 4. Retrieval augmentation: if the application uses RAG, relevant document chunks are retrieved from a vector store and inserted into the context window at this stage (see RAG Architecture). 5. Conversation history injection: prior turns from the session are prepended to maintain conversational continuity. 6. Token budget check: the assembled prompt is tokenized and measured against the model's context window limit. If the budget is exceeded, older history turns are truncated. 7. Cache key computation: a deterministic hash of the assembled prompt is computed to enable Prompt Cache System lookups. 8. Cache hit?: if an exact match exists in the prompt cache, the cached response is returned immediately, bypassing the model entirely. 9. LLM request: the final assembled prompt is dispatched to the model via the LLM Request Flow. 10. Response post-processing: the raw model output is parsed, formatted, and optionally passed through a moderation filter before being returned to the caller.
Why this matters
The quality of what a model produces is directly bounded by the quality of what it receives. A well-designed prompt processing pipeline ensures consistency, safety, and cost efficiency across every inference call.