LLM Request Flow
An LLM request flow describes the end-to-end lifecycle of a single inference call — from the moment a client application sends a prompt to the moment a generated response is returned and logged.
An LLM request flow describes the end-to-end lifecycle of a single inference call — from the moment a client application sends a prompt to the moment a generated response is returned and logged.
What the diagram shows
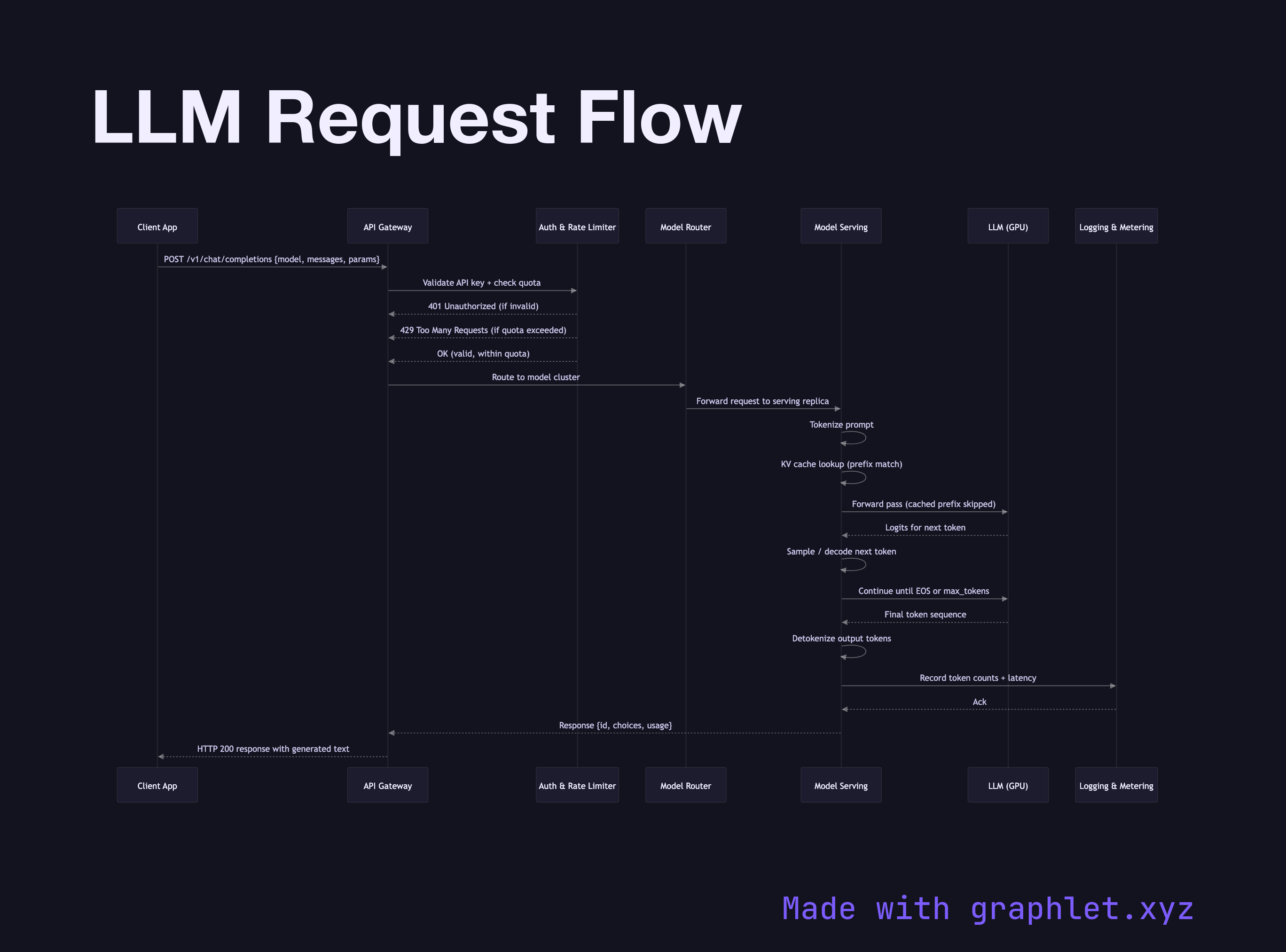
This sequence diagram traces the path a request takes through each layer of a production LLM stack:
1. Client → API Gateway: the application sends an HTTP POST carrying the model identifier, messages array, and parameters such as temperature and max tokens. 2. Authentication & rate limiting: the gateway validates the API key and enforces per-user or per-organization token quotas. Rejected requests receive a 401 or 429 before reaching the model. 3. Request routing: the gateway forwards the validated request to the appropriate model serving cluster, selecting the correct model version and region. 4. Tokenization: the serving layer converts the raw text prompt into a sequence of integer tokens using the model's tokenizer. 5. KV cache lookup: the serving layer checks whether a prefix of the token sequence is already cached in GPU memory, avoiding redundant computation for repeated context. 6. Model inference: the transformer performs a forward pass, producing logit distributions over the vocabulary at each output position. 7. Sampling / decoding: a decoding strategy (greedy, top-p, or beam search) selects the next token until an end-of-sequence token is produced or the max token limit is reached. 8. Detokenization: the output token IDs are converted back to text. 9. Logging & metering: token counts and latency are recorded for billing and observability. 10. Response: the final text is returned to the client, wrapped in the API response envelope.
Why this matters
Understanding the full request path helps engineers identify where latency is introduced — whether in network overhead, tokenization, KV cache misses, or pure model compute. It also clarifies which layers are responsible for safety, cost control, and observability.
For streaming variants see LLM Streaming Response. To understand how the prompt itself is assembled before the request is sent, see Prompt Processing Pipeline. The caching layer is explored in depth in Prompt Cache System.