Vector Database Query
A vector database query is the process of finding the most semantically similar stored vectors to a query vector using approximate nearest-neighbor (ANN) search, enabling fast retrieval across millions of embeddings.
A vector database query is the process of finding the most semantically similar stored vectors to a query vector using approximate nearest-neighbor (ANN) search, enabling fast retrieval across millions of embeddings.
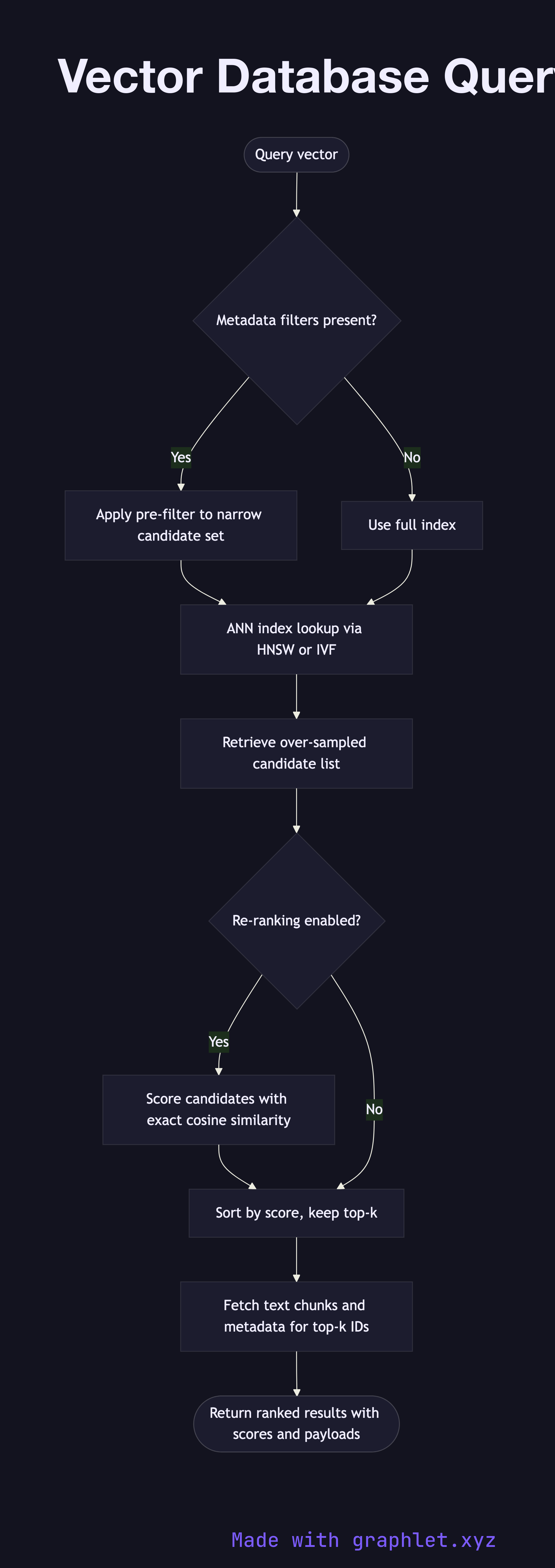
What the diagram shows
This flowchart details the internal execution path of a vector database query from input to ranked results:
1. Query vector: a dense float vector (typically 768–3072 dimensions) arrives, generated by an embedding model from the raw user query (see Embedding Generation Flow). 2. Metadata filter pre-check: if the query includes metadata filters (e.g., source = "docs" or date > 2024-01-01), the database narrows the candidate set before the ANN search. 3. ANN index lookup: the query vector is compared against the indexed vectors using an ANN algorithm such as HNSW (Hierarchical Navigable Small World) or IVF (Inverted File Index). This trades exact results for orders-of-magnitude faster search. 4. Candidate retrieval: the ANN pass returns an over-sampled set of candidates — more than the final k requested — to allow re-ranking. 5. Re-ranking: candidates are optionally re-ranked using a more precise similarity metric (e.g., exact cosine similarity or a cross-encoder model) to improve result quality. 6. Fetch payloads: the database retrieves the stored payload — original text chunks and metadata — for each final result. 7. Return top-k results: the results, ordered by similarity score, are returned to the calling application.
Why this matters
ANN indexes make it possible to search millions of vectors in milliseconds. Understanding the query execution path helps engineers tune index parameters, filter strategies, and re-ranking tradeoffs that directly impact retrieval quality and latency. For the full RAG context see RAG Architecture.