RAG Architecture
Retrieval-Augmented Generation (RAG) is an architectural pattern that grounds language model responses in external knowledge by retrieving relevant documents at inference time and injecting them into the prompt before generation.
Retrieval-Augmented Generation (RAG) is an architectural pattern that grounds language model responses in external knowledge by retrieving relevant documents at inference time and injecting them into the prompt before generation.
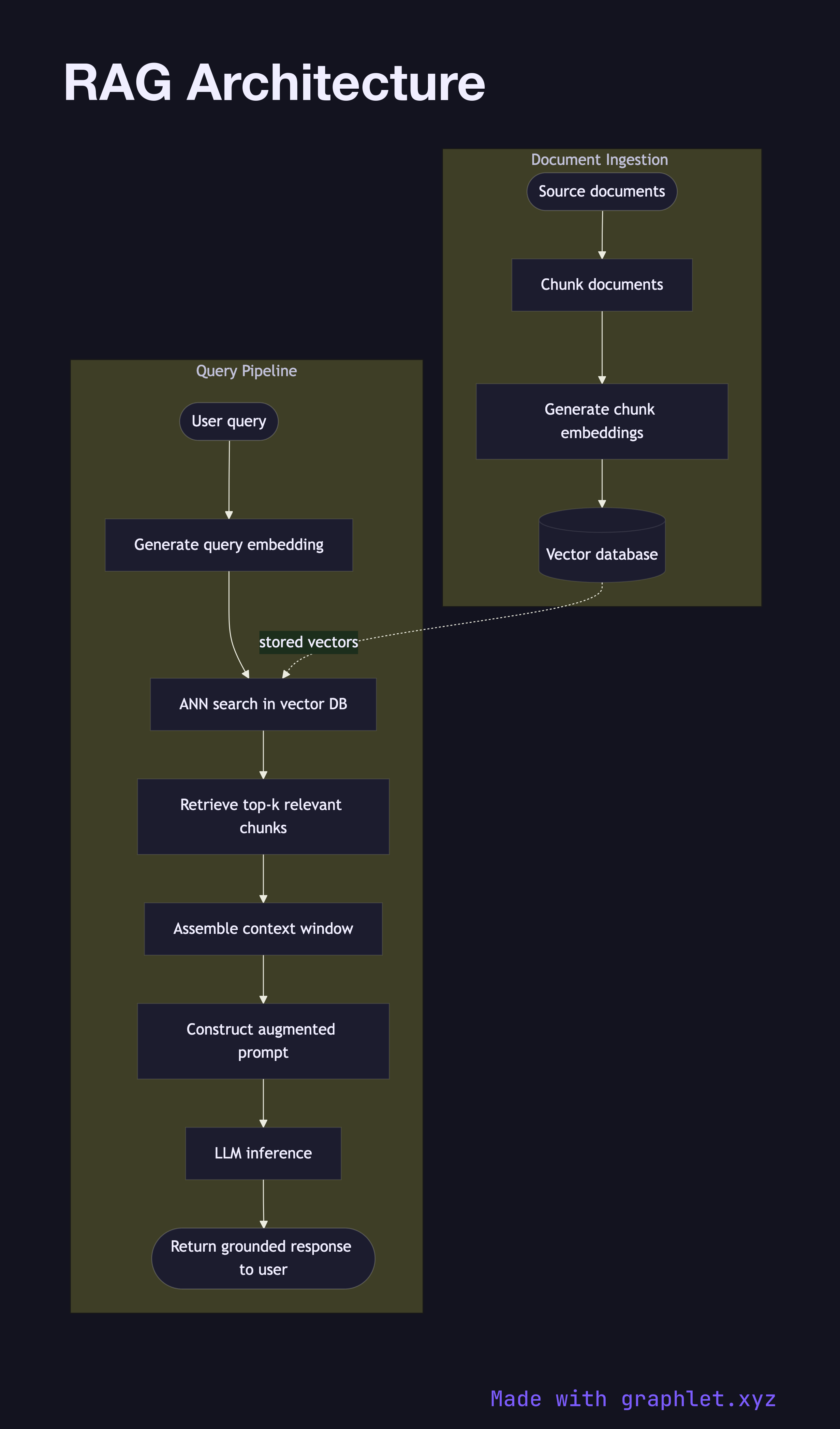
What the diagram shows
The diagram captures both the document ingestion pipeline (run offline or continuously) and the query pipeline (run on every user request):
Ingestion pipeline: 1. Source documents — web pages, PDFs, database exports, knowledge bases — enter the pipeline. 2. Documents are split into overlapping chunks small enough to fit within the embedding model's context window. 3. Each chunk is converted into a dense vector by an embedding model (see Embedding Generation Flow). 4. Vectors and their associated text payloads are written to a vector database (see Vector Database Query).
Query pipeline: 1. A user query arrives at the application. 2. The query is embedded using the same embedding model as the documents, producing a query vector. 3. The vector database returns the top-k most similar chunks via approximate nearest-neighbor search. 4. The retrieved chunks are assembled into a context window alongside the user's question. 5. An augmented prompt — system instructions + retrieved context + user query — is constructed and dispatched to the LLM (see LLM Request Flow). 6. The LLM generates a grounded response that cites information from the retrieved context.
Why this matters
RAG dramatically reduces hallucinations by giving the model accurate, up-to-date information at generation time, without requiring expensive fine-tuning. It also makes answers auditable — every claim can be traced back to a retrieved source chunk.