Prompt Cache System
A prompt cache system stores previously computed LLM responses keyed by a deterministic hash of the input prompt, enabling instant cache-hit responses that bypass the model entirely — reducing both latency and per-token inference costs.
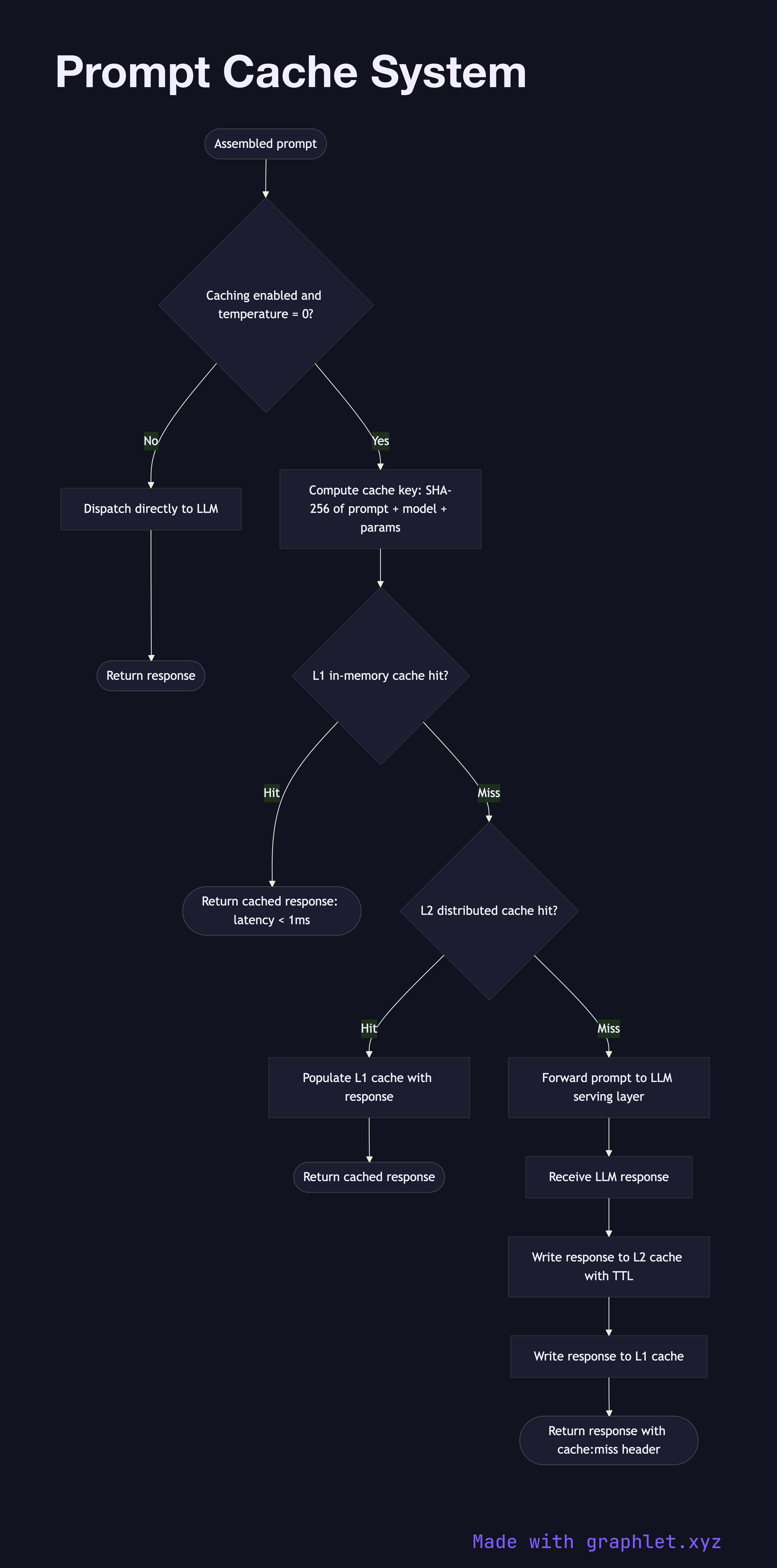
A prompt cache system stores previously computed LLM responses keyed by a deterministic hash of the input prompt, enabling instant cache-hit responses that bypass the model entirely — reducing both latency and per-token inference costs.
What the diagram shows
This flowchart details the read and write paths of a two-tier prompt caching architecture:
1. Incoming prompt: a fully assembled prompt (after Prompt Processing Pipeline has run) arrives at the caching layer. 2. Cache key computation: a canonical hash (e.g., SHA-256) is computed from the prompt contents, model identifier, and key generation parameters such as temperature. Requests with temperature > 0 may be excluded from caching since outputs are non-deterministic. 3. L1 cache lookup (in-memory): the hash is looked up in a fast in-memory store (Redis or local LRU cache). If found, the response is returned immediately. 4. L2 cache lookup (distributed): on an L1 miss, the lookup falls through to a distributed cache layer (e.g., a shared Redis cluster or object store index). 5. Cache miss → LLM dispatch: on a full cache miss, the prompt is forwarded to the LLM serving layer (see LLM Request Flow). 6. Response received: the LLM returns the generated text. 7. Cache write: the response is written to both L1 and L2 caches under the computed key, with a TTL appropriate to the content's expected freshness. 8. Return response: the response is returned to the caller, flagged with a cache: miss or cache: hit header for observability.
Why this matters
For applications where identical or near-identical prompts are common — documentation Q&A, template-based generation, repeated system prompts — a prompt cache can reduce LLM API costs by 40–80% and cut response latency from seconds to milliseconds.