Data Lake Architecture
A data lake architecture is a storage and processing system that centralizes raw data from all sources in its native format, then applies structure progressively as data moves toward serving layers — deferring schema decisions until the data is actually queried.
A data lake architecture is a storage and processing system that centralizes raw data from all sources in its native format, then applies structure progressively as data moves toward serving layers — deferring schema decisions until the data is actually queried.
The key difference between a data lake and a data warehouse is the point at which schema is enforced. A warehouse enforces schema on write: data must be cleaned and structured before it is loaded. A data lake enforces schema on read: raw data lands in the lake immediately, and structure is applied when a job or query reads it. This makes the lake far more flexible — you can store data before you know exactly how you will use it.
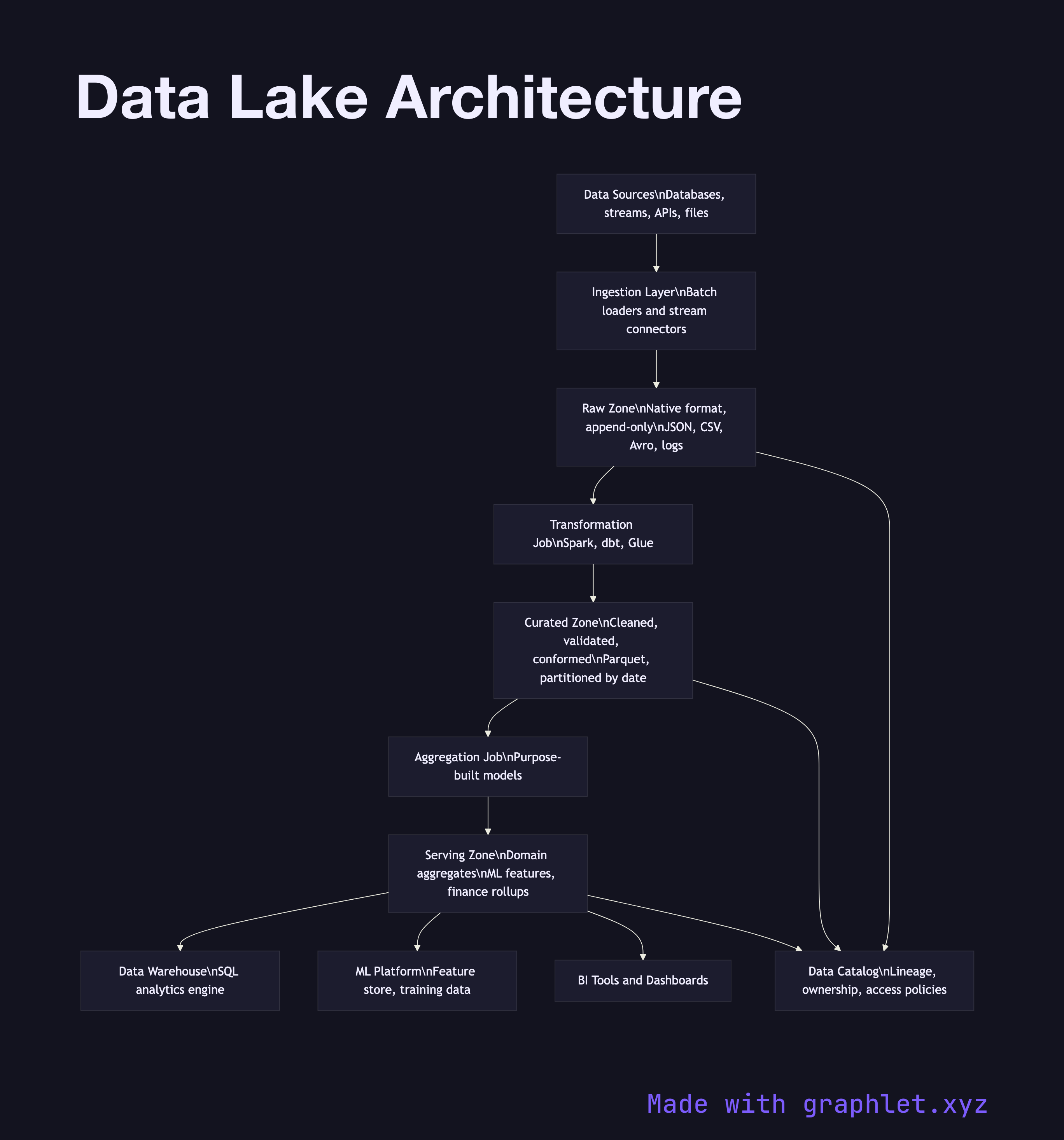
Modern data lake architectures are organized into zones that represent progressive levels of curation. The raw zone (also called the landing or bronze zone) is an append-only store of source data exactly as it arrived — JSON blobs, CSV exports, Avro records, application logs. Nothing is deleted or modified here; this is the system of record for replay.
The curated zone (silver zone) contains data that has been cleaned, validated, and conformed by a transformation job. Schemas are enforced at this layer, duplicate records are removed, and source-specific quirks are normalized. Data here is stored in an efficient columnar format such as Parquet or ORC, partitioned by date and entity type to minimize query scan costs.
The serving zone (gold zone) contains purpose-built aggregates and dimensional models optimized for specific use cases: a user activity summary table for the product team, a revenue rollup for finance, a feature table for the machine learning platform. These are derived from the curated zone and are rebuilt on a schedule via a transformation framework like Spark or dbt.
A catalog and governance layer runs across all zones, tracking dataset lineage, ownership, and access policies. See Data Warehouse Pipeline for how a warehouse complements the lake as the primary analytical query engine, and ETL Workflow for the transformation jobs that promote data between zones.