ETL Workflow
An ETL (Extract, Transform, Load) workflow is a three-phase data integration process that extracts raw data from source systems, applies transformations to make it consistent and useful, and loads the result into a target store for analysis.
An ETL (Extract, Transform, Load) workflow is a three-phase data integration process that extracts raw data from source systems, applies transformations to make it consistent and useful, and loads the result into a target store for analysis.
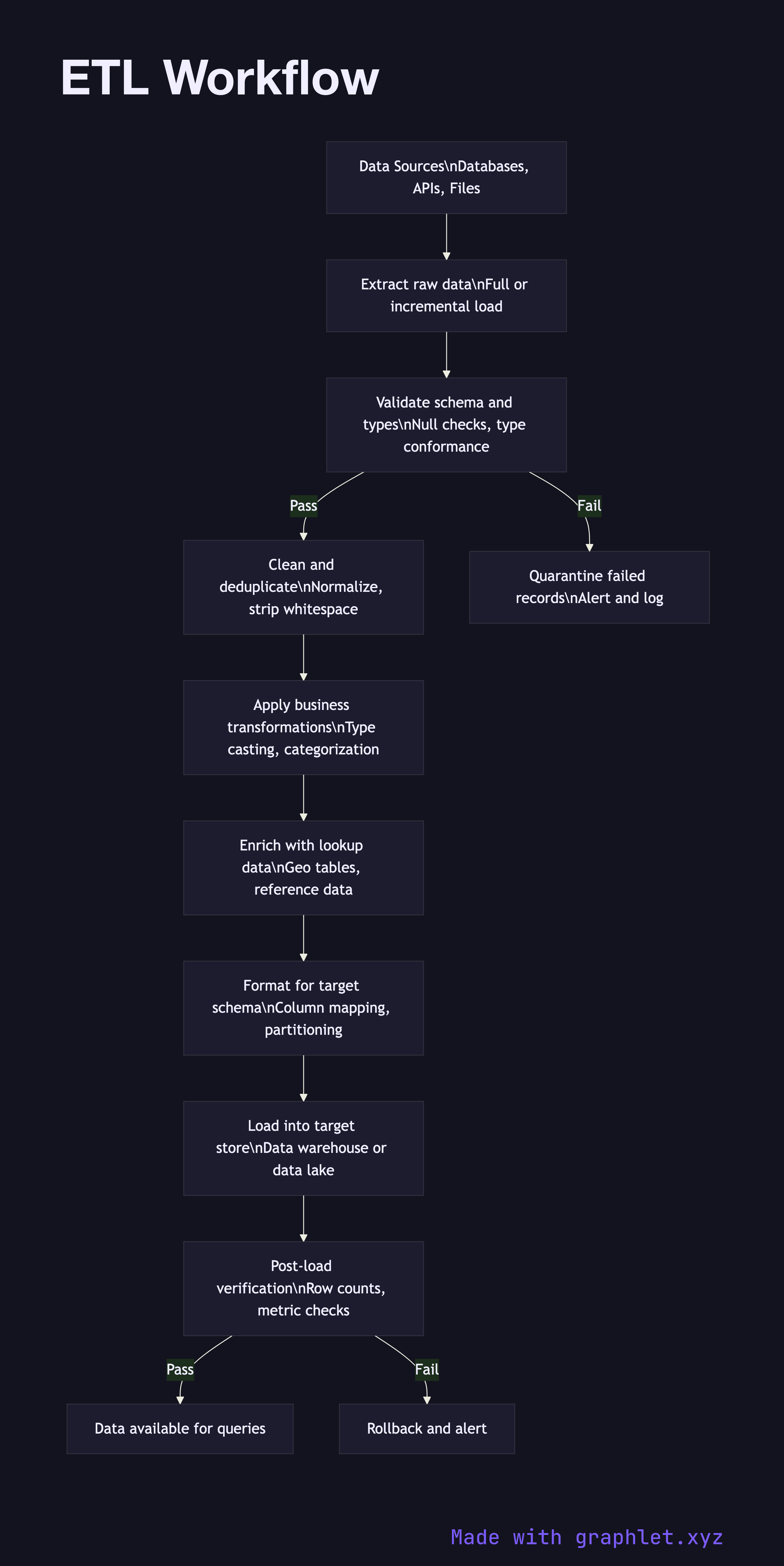
ETL is one of the most foundational patterns in data engineering. Before a single analyst can run a query or a dashboard can render a chart, raw data from production systems must be moved, reshaped, and quality-checked. The ETL workflow defines exactly how that happens.
Extract is the first phase. The job connects to one or more source systems — databases, APIs, flat files, or streaming topics — and pulls data. Depending on the source, extraction may be a full snapshot (all rows every run) or incremental (only rows changed since the last watermark). Incremental extraction is faster and cheaper but requires the source to expose a reliable change indicator such as an updated_at timestamp or a CDC log.
Validate follows immediately after extraction. Before any transformation is applied, the pipeline confirms that the incoming data conforms to expected types and constraints: are required fields present? Do numeric columns contain numeric values? Are foreign key references resolvable? Records that fail validation are quarantined rather than silently dropped, so data quality issues surface as alerts rather than silent gaps in reports.
Transform is the most complex phase. It encompasses cleaning (stripping whitespace, normalizing casing), deduplication (removing records with identical business keys), type casting (parsing ISO timestamps into date objects), business logic application (categorizing orders by size tier), and enrichment (joining in reference data like country names from a geo lookup table). Well-designed transformations are idempotent — running the same job twice produces the same result — which makes reruns safe.
Load writes the transformed records into the target: a Data Warehouse Pipeline, a Data Lake Architecture, or a downstream API. A post-load verification step checks row counts and key metrics against expected ranges. If any check fails, the load is rolled back and the job is marked as failed rather than silently corrupting the destination. Data Ingestion Pipeline covers the broader infrastructure that schedules and orchestrates ETL jobs across many sources.