Search Indexing Pipeline
A search indexing pipeline is the sequence of processing stages that transforms raw content — web pages, product listings, documents — into an inverted index that can be queried in milliseconds.
A search indexing pipeline is the sequence of processing stages that transforms raw content — web pages, product listings, documents — into an inverted index that can be queried in milliseconds.
How the pipeline works
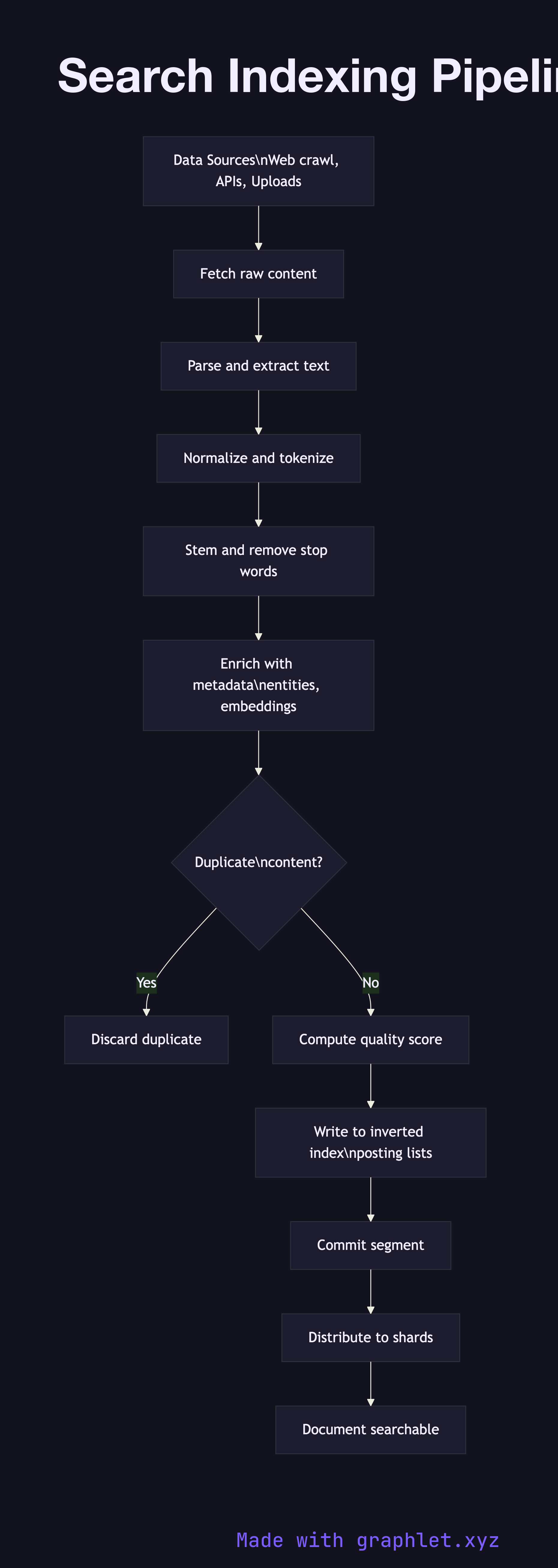
Data ingestion is the entry point. Content arrives from multiple sources: a web crawler fetching URLs from a frontier queue, upstream APIs pushing new records, or direct file uploads from content teams. Each source produces raw bytes that the pipeline must normalize before any linguistic processing can happen.
Fetch and parse extracts structured text from the raw payload. An HTML page is stripped of markup, scripts, and boilerplate navigation. A PDF is converted to plain text. JSON payloads are field-mapped. The goal is a clean document object with a URL or ID, a body, and optional structured fields like title, author, and publication date.
Normalize and tokenize applies text processing: Unicode normalization, lowercasing, whitespace collapsing, and splitting the body into individual tokens (words or sub-word pieces). A tokenizer configured for English will split on whitespace and punctuation; a multilingual tokenizer may apply language detection first and then use a language-appropriate segmenter.
Enrichment augments the token stream with signals that improve ranking later. Common enrichments include stemming or lemmatization (mapping "running" → "run"), stop-word removal, synonym expansion, entity extraction (identifying product names, locations, or people), and embedding generation for semantic search.
Deduplication checks a content hash or near-duplicate fingerprint (e.g., a SimHash or MinHash value) against the existing index. Duplicate or near-duplicate documents are discarded or merged to avoid cluttering result pages with copies.
Write to inverted index posts each token to the index as a posting list entry: the term, the document ID, the position in the document, and optional frequency data. Modern search engines like Elasticsearch and Solr use Lucene segments for this; each segment is an immutable mini-index that gets merged periodically.
Shard distribution assigns documents to shards based on a routing key. The Search Sharding Architecture diagram shows how this distribution works. Once a document lands on a shard and the shard's segment is refreshed or committed, the document becomes visible to the Search Query Processing path. Indexing latency — the time between content creation and searchability — is a key operational SLO for any real-time search system.